DBN과 BLSTM을 이용한 시계열 의존성 학습
초록
본 논문은 딥러닝 기반의 DBN과 양방향 LSTM을 결합한 DBN‑BLSTM 구조를 제안한다. 이 모델은 시계열 데이터의 장기 의존성을 효과적으로 포착하면서도 DBN이 제공하는 깊은 계층적 표현을 유지한다. 음악 생성 실험에서 기존 모델들을 크게 능가하는 로그‑우도 성능을 기록하며, 특히 다중 음표를 포함한 폴리포닉 음악 생성에 강점을 보인다.
상세 분석
제안된 DBN‑BLSTM은 두 개의 주요 구성요소, 즉 제한 볼츠만 머신(RBM) 기반의 Deep Belief Network(DBN)와 양방향 Long Short‑Term Memory(BLSTM) 네트워크를 결합한다. DBN은 여러 층의 RBM을 순차적으로 사전학습(greedy pre‑training)함으로써 입력 데이터의 고차원 구조를 비지도 방식으로 추출한다. 이때 각 RBM은 에너지 함수 E(v,h)=−bᵥᵀv−bₕᵀh−hᵀWv 로 정의되며, 대조 발산(CD‑k) 알고리즘을 통해 파라미터를 업데이트한다.
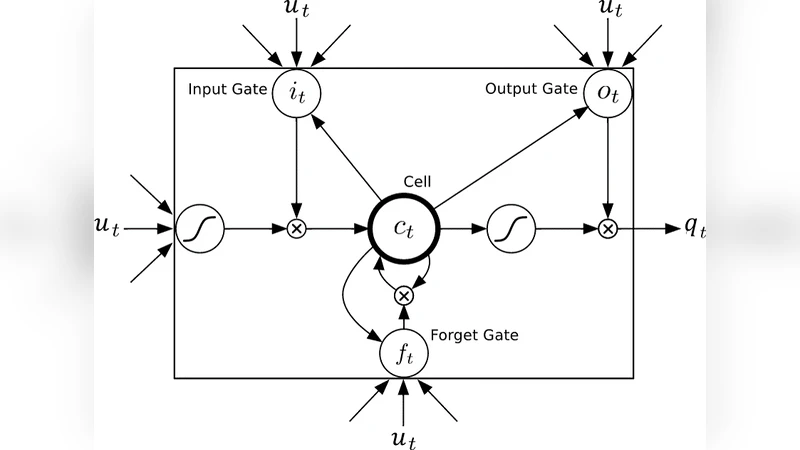
BLSTM은 순방향과 역방향 LSTM을 동시에 운영해 시퀀스의 과거와 미래 정보를 모두 활용한다. 각 LSTM 셀은 입력 게이트 iₜ, 망각 게이트 fₜ, 출력 게이트 oₜ, 셀 상태 cₜ 로 구성되며, 수식 (5)‑(10)에 명시된 바와 같이 시계열 의존성을 장기적으로 보존한다.
두 네트워크 간의 상호작용은 두 단계로 구현된다. 첫째, BLSTM의 은닉 상태 qₜ와 입력 uₜ를 이용해 DBN 각 층의 바이어스를 동적으로 조정한다. 구체적으로 가시층 바이어스 bᵥₜ는 bᵥ₀+W_{uv} u_{t‑1}+W_{qv} q_{t‑1} 로, n번째 은닉층 바이어스 b_{h}^{(n)}ₜ는 b_{h}+W_{uh}^{(n)} u_{t‑1}+W_{qh}^{(n)} q_{t‑1} 로 계산된다(식 12‑13). 이 과정은 BLSTM이 학습한 시간적 컨텍스트를 DBN의 확률 모델에 직접 주입함으로써, 시계열 특성을 반영한 계층적 표현을 가능하게 한다.
둘째, 각 시간 단계 t에서 DBN은 입력 vₜ(음표 존재 여부를 나타내는 88차원 이진 벡터)를 받아 전방향 샘플링을 수행한다. 샘플링은 RBM의 Gibbs 샘플링 절차(식 2)를 이용해 이루어지며, 이렇게 생성된 vₜ₊₁는 다음 시간 단계의 BLSTM 입력으로 재사용된다. 따라서 DBN과 BLSTM이 교차 피드백 루프를 형성해 순환적 생성 과정을 구현한다.
실험에서는 3개의 은닉 DBN 층(각 150개의 이진 유닛)과 150개의 유닛을 갖는 BLSTM을 사용했으며, 드롭아웃을 각 층에 적용해 과적합을 방지하였다. 네 개의 MIDI 기반 데이터셋(JSB Chorales, MuseData, Nottingham, Piano‑Midi.de)에서 로그‑우도(LL) 기준으로 기존 RNN‑RBM, RNN‑DBN, N‑ADE 등과 비교했을 때, DBN‑BLSTM은 각각 –3.47, –3.91, –1.32, –4.63이라는 최우수 점수를 기록했다. 이는 시계열 의존성을 효과적으로 모델링하면서도 깊은 표현 학습을 유지한 결과로 해석된다.
본 연구의 주요 기여는 (1) DBN과 BLSTM을 통합해 시간적·구조적 정보를 동시에 학습하는 새로운 아키텍처 제시, (2) 바이어스 조정을 통한 두 모델 간의 효율적 정보 교환 메커니즘 설계, (3) 음악 생성이라는 복합 시퀀스 생성 태스크에서 현존 최고 성능 달성이다. 향후 연구에서는 Gaussian 가시층을 도입해 연속형 오디오 신호에 확장하거나, Transformer와 같은 최신 시퀀스 모델과의 하이브리드도 탐색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기