GPU 기반 해밍 디코더 고속 구현 및 실시간 SDR 적용
초록
본 논문은 해밍 코드 디코딩을 GPU에서 효율적으로 수행하도록 설계·최적화한 방법을 제시한다. 데이터가 희소하게 배치되고 조건문이 많아 메모리 접근이 비공격적이며 스레드 발산이 심한 기존 알고리즘의 문제점을, CPU‑GPU 전처리, 비동기 전송, 공동 메모리 활용, 연산 트리 기반 감산 등으로 해결한다. 실험 결과 GTX 560 기준 CPU 대비 최대 99배 가속을 달성했으며, 패킷 크기·오류 허용 범위에 따라 일관된 성능 향상을 보였다.
상세 분석
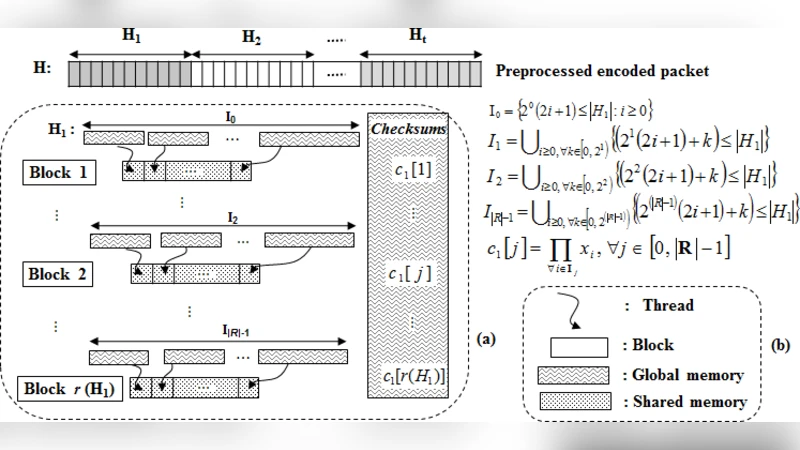
해밍 디코더는 오류 검출·수정에 필요한 체크섬 비트를 계산하고, 오류 위치를 찾아 원본 데이터를 복원하는 3단계(분할‑디코드‑병합) 구조를 가진다. 이 과정은 원본 패킷을 여러 세그먼트로 나누고, 각 세그먼트에 대해 비트 인덱스 집합 I₀…I_{R‑1}을 이용해 XOR 연산을 수행한다. 인덱스가 비연속적이기 때문에 GPU 전역 메모리에서 비공격적(coalesced) 접근이 불가능하고, 조건문에 의한 스레드 발산이 크게 발생한다. 논문은 이러한 병목을 크게 세 단계로 해소한다.
첫째, CPU에서 사전 전처리를 수행해 희소 비트를 연속적인 클러스터(h₁, h₂, …) 로 재배열한다. 재배열된 데이터는 전역 메모리에서 연속적으로 읽히므로 메모리 대역폭을 최대로 활용할 수 있다. 둘째, 데이터 전송은 동기식(SDT) 대신 비동기식(ADT) 파이프라인을 적용해 패킷 전송·커널 실행·결과 수신을 겹치게 함으로써 전송 오버헤드를 절반 이하로 감소시켰다. 셋째, 실제 디코딩은 두 개의 CUDA 커널로 구현한다. 체크섬 커널은 각 세그먼트를 블록 단위로 할당하고, 공유 메모리에 복사한 뒤 XOR 연산을 트리 형태로 수행해 은닉된 은행 충돌을 방지한다. 오류·수정·중복 제거 커널은 체크섬 결과를 기반으로 오류 비트를 식별하고, 필요한 경우 비트를 토글해 원본 데이터를 복원한다. 이때도 공유 메모리를 중심으로 연산을 진행해 전역 메모리 접근을 최소화한다.
성능 평가에서는 400 ~ 2000 바이트 패킷과 오류 허용 비트 t = 26을 대상으로 실험했으며, GPU 구현은 패킷 크기에 거의 민감하지 않은 일정한 실행 시간을 보였다. 반면 CPU 구현은 패킷 길이와 오류 비트 수가 증가함에 따라 선형적으로 지연이 늘어났다. 특히 오류 허용 비트가 커질수록 세그먼트 수가 늘어나 GPU의 병렬 처리 효율이 더욱 돋보였다. 최종적으로 GTX 560(336 코어)에서 최대 99배, 평균 4070배 정도의 속도 향상을 기록했다. 이러한 결과는 해밍 디코딩이 실시간 SDR, 고속 무선 통신, 위성·수중 통신 등 지연 민감 애플리케이션에 GPU 기반 가속을 적용할 충분한 근거를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기