FPGA 클러스터에서 진화 알고리즘 구현을 통한 대규모 네트워크 최적화
초록
본 논문은 Node‑Depth Encoding(NDE) 기반 진화 알고리즘을 FPGA 단일 보드에서 512노드까지 구현한 기존 시스템을 확장하여, 중앙 FPGA와 다수의 위성 FPGA가 별도 링크로 연결되는 스타 토폴로지를 구성함으로써 4096노드 규모의 그래프 최소 신장 트리를 실시간에 가깝게 해결할 수 있음을 보인다.
상세 분석
이 연구는 네트워크 설계 문제, 특히 전력·통신망과 같이 노드 수가 수천에서 수만에 달하는 그래프에서 차수 제한이 있는 최소 신장 트리(DC‑MST)를 찾는 NP‑Hard 문제에 초점을 맞춘다. 기존의 CPU 기반 알고리즘은 O(n log n) 정도의 복잡도를 가지지만, 차수 제한이 가해지면 탐색 공간이 급격히 확대돼 실시간 적용이 어렵다. 저자들은 이러한 한계를 극복하기 위해 진화 알고리즘(EA)의 표현 방식을 Node‑Depth Encoding(NDE)으로 채택한다. NDE는 트리를 (노드, 깊이) 쌍의 선형 리스트로 변환함으로써 트리 구조를 압축하고, 연산자 Preserve Ancestor Operator(PAO)를 적용해 두 트리를 교차 변형시켜 새로운 후보 해를 생성한다. 이때 PAO는 깊이 정보를 보존하면서 차수 제한을 자동으로 검증하므로, 후보 해의 타당성을 빠르게 판단할 수 있다.
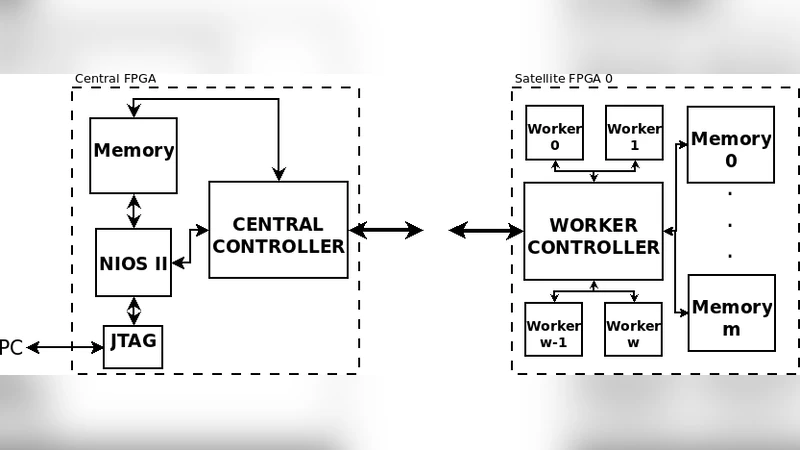
하드웨어 구현 측면에서 저자들은 기존에 Altera Cyclone II와 Stratix IV GX에 구현된 NDEWG 플랫폼을 분석한다. 해당 플랫폼은 ‘워커(Worker)’라 불리는 병렬 처리 유닛이 그래프의 엣지를 순차적으로 처리하며, 워커 수를 √n 개까지 늘리면 이론적으로 O(1) 시간 복잡도에 근접한다. 그러나 워커는 FPGA 내부의 논리와 메모리 자원을 직접 사용하므로, 노드 수가 1024를 초과하면 버스 폭과 온칩 메모리 한계에 봉착한다. 이를 해결하기 위해 저자들은 중앙 FPGA가 전체 트리 관리와 작업 스케줄링을 담당하고, 다수의 위성 FPGA가 워커 풀을 제공하는 스타 구조를 설계했다. 중앙‑위성 간 통신은 10 Gbps Ethernet 인터페이스와 XAUI PHY를 이용해 구현했으며, 네트워크 추상화 시스템(NAS)을 도입해 메모리‑맵드 I/O를 스트리밍 버스로 변환함으로써 하드웨어 간 데이터 전송을 일관되게 처리한다.
실험 결과, 시뮬레이션 단계에서는 메모리 지연을 무시한 채 평균 반복 시간 0.144 µs를 기록했으며, 실제 하드웨어에서는 NAS와 Ethernet 지연으로 인해 85 µs 수준으로 감소하였다. 이는 네트워크 스택이 전체 성능의 병목임을 시사한다. 또한, 1, 4, 8개의 위성 모듈을 구성했을 때 논리 요소 사용량과 최대 클럭 주파수가 각각 174 MHz→122 MHz로 감소했지만, 속도 향상 비율은 1.0×→1.73×에 머물렀다. 4096노드까지 확장했을 때는 온칩 메모리 부족으로 8192노드는 구현하지 못했으며, 이는 향후 고밀도 메모리 또는 외부 DRAM 인터페이스 도입이 필요함을 의미한다.
결론적으로, FPGA 클러스터 기반의 NDE‑EA는 차수 제한이 있는 대규모 MST 문제에 대해 CPU 대비 높은 처리량을 제공하지만, 현재 구현에서는 네트워크 인터페이스와 메모리 자원의 제약이 주요 제한 요소이다. 향후 연구에서는 NAS의 경량화, 고속 전용 버스 설계, 그리고 메모리 계층 구조 최적화를 통해 확장성을 더욱 강화할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기