편향 없는 특징 학습을 위한 MMD 기반 프레임워크
초록
본 논문은 최대 평균 차이(MMD)를 이용해 데이터 표현을 “편향 없이” 만들고, 이를 도메인 적응, 조명 불변 얼굴 인식, 잡음에 강인한 오토인코더, 그리고 생성 모델 학습에 적용한다. 실험 결과 MMD 페널티가 기존 방법보다 높은 전이 성능과 불변성을 제공함을 보인다.
상세 분석
본 연구는 전이 학습에서 핵심적인 표현 학습을 “편향(unbiased)”이라는 새로운 관점으로 재정의한다. 여기서 편향이란 특정 작업, 도메인, 혹은 데이터의 불필요한 변동성에 과도하게 의존하는 것을 의미한다. 저자들은 이러한 편향을 정량화하기 위해 두 표본 검정에 기반한 최대 평균 차이(MMD)를 선택한다. MMD는 커널 함수를 이용해 두 확률분포 사이의 거리(또는 차이)를 측정하며, 보편적인 재생 커널 힐베르트 공간에서 P=Q 일 때만 0이 된다. 이 특성을 활용해 신경망의 중간 층에 MMD 페널티를 부과하면, 서로 다른 도메인 혹은 변형된 데이터 집합의 특징 분포를 강제로 일치시킬 수 있다.
첫 번째 적용은 도메인 적응이다. 아마존 리뷰 데이터(책, DVD, 전자제품, 주방)의 네 도메인 간 전이에서, 기존 SVM, TCA 등과 비교해 MMD를 적용한 2‑계층 신경망이 대부분의 소스‑타깃 조합에서 최고 정확도를 기록한다. 특히 단어 카운트와 같은 저차원 특징에서도 MMD가 효과적으로 도메인 차이를 억제한다는 점이 주목된다.
두 번째는 조명 변동에 대한 불변 특징 학습이다. Extended Yale‑B 데이터셋을 5개의 조명 조건(도메인)으로 나누어, 각 도메인별 특징 분포와 전체 평균 분포 사이의 MMD를 최소화한다. 결과적으로 2번째 은닉층의 표현이 조명에 관계없이 동일 인물의 이미지들을 클러스터링했으며, 테스트 정확도가 72%에서 82%로 크게 상승했다. 이는 MMD가 명시적인 라이트 모델 없이도 복잡한 변환에 대한 불변성을 학습시킬 수 있음을 보여준다.
세 번째는 잡음에 강인한 오토인코더이다. 기존의 DAE와 CAE는 각각 잡음 복원과 미분 가능한 계약을 목표로 하지만, MMD 페널티를 추가한 오토인코더는 은닉 표현의 분포 자체를 잡음 전후에서 일치시킨다. MNIST 실험에서, 잡음이 섞인 테스트 데이터를 구분하는 SVM의 정확도가 78.6%→72.9%로 감소했으며, 이는 학습된 특징이 잡음에 대해 보다 불변임을 의미한다. 흥미롭게도 DAE는 오히려 잡음 구분 정확도를 높여, 잡음 복원이 반드시 불변성을 보장하지 않음을 시사한다.
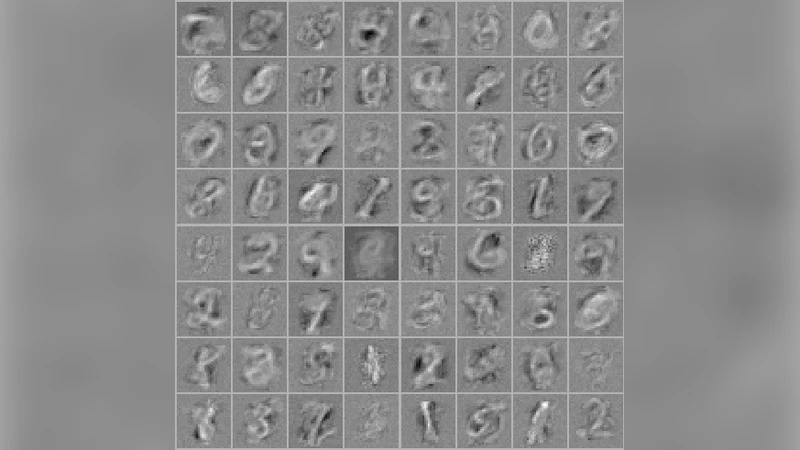
마지막으로 MMD를 이용한 생성 모델 학습을 제안한다. 기존 GAN은 미니맥스 게임으로 학습이 불안정한 반면, 저자는 고정된 잠재 변수 샘플에 대해 MMD를 직접 최소화함으로써 단일 목표 함수만으로 모델을 최적화한다. 1000개의 MNIST 샘플에 대해 학습된 모델은 의미 있는 저차원 특징을 학습하고, 시각적으로도 현실적인 손글씨 이미지를 생성한다.
전반적으로 논문은 MMD를 다양한 학습 시나리오에 일관되게 적용함으로써, “편향 없는” 특징을 정의하고 실험적으로 검증한다. 강점은 MMD가 비지도·반지도 학습 모두에 적용 가능하고, 커널 선택에 따라 선형·비선형 불변성을 조절할 수 있다는 점이다. 한계는 MMD 계산 비용이 샘플 수에 비례해 증가한다는 점과, 커널 하이퍼파라미터 튜닝이 성능에 큰 영향을 미친다는 점이다. 향후 연구에서는 대규모 데이터에 대한 효율적인 근사 MMD 방법과, 다중 편향(예: 도메인·노이즈·변형)을 동시에 최소화하는 다중 목표 프레임워크가 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기