Hive 업데이트 최적화를 위한 하이브리드 스토리지 모델 DualTable
초록
Hive는 대규모 배치 분석에 강점이 있지만 HDFS 기반 저장소의 쓰기‑once 특성 때문에 UPDATE·DELETE와 같은 행 수준 데이터 조작이 비효율적이다. 본 논문은 HDFS의 순차 읽기 성능과 HBase의 랜덤 쓰기 능력을 결합한 DualTable이라는 하이브리드 스토리지 모델을 제안한다. 마스터 테이블은 HDFS에, 변경·삭제 기록은 HBase에 저장하고, 비용 모델 기반 적응형 전략으로 UPDATE/DELETE 구현 방식을 선택한다. UNION‑READ를 통해 두 저장소를 투명하게 병합하고, 주기적인 COMPACT로 성능 저하를 방지한다. TPC‑H와 실제 스마트 그리드 데이터셋 실험에서 기존 Hive 대비 업데이트·삭제 속도가 최대 10배 향상되었음을 입증한다.
상세 분석
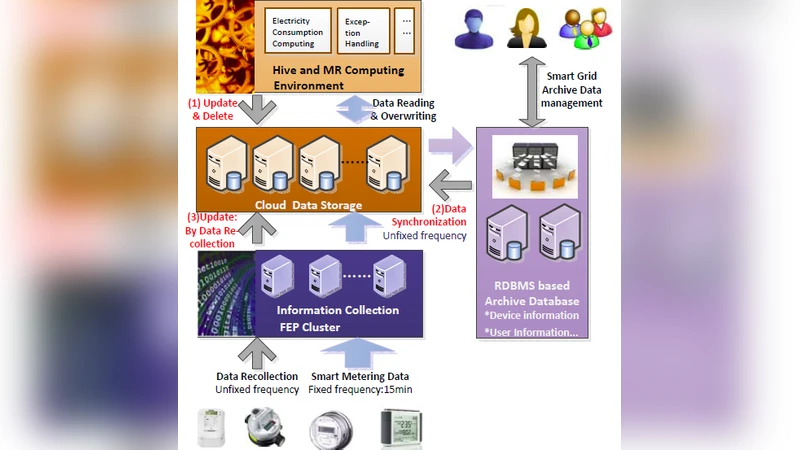
Hive가 대용량 로그와 정형 데이터를 배치 처리하는 데는 탁월하지만, HDFS가 “쓰기‑once, 읽기‑다수” 구조를 채택함에 따라 행 수준의 수정 작업은 전체 파일을 재작성해야 하는 INSERT OVERWRITE 방식으로 전락한다. 이는 업데이트 대상 레코드가 전체의 1 % 미만인 경우에도 수십 GB‑TB 규모의 파일을 전부 읽고 다시 쓰는 비효율을 초래한다. 반면 HBase는 key‑value 기반으로 레코드 단위의 랜덤 쓰기를 지원하지만, 스캔 성능이 HDFS에 비해 현저히 낮아 대규모 분석 쿼리에서는 병목이 된다. 기존 Hive‑5317 ACID 구현은 베이스 테이블과 여러 delta 테이블을 동일 포맷(HDFS)으로 저장해, 업데이트 시 delta를 추가하는 방식이지만 근본적인 I/O 비용 감소에 한계가 있다.
DualTable은 이러한 구조적 한계를 “마스터 테이블(HDFS) + 어태치드 테이블(HBase)”라는 두 레이어로 분리한다. 마스터 테이블은 초기 로드 시 전체 데이터를 HDFS에 저장해 순차 읽기와 대용량 스캔을 최적화하고, 어태치드 테이블은 업데이트·삭제 레코드만 HBase에 기록한다. 각 레코드는 전역 고유 ID(row‑id)로 마스터와 어태치드 사이에 1:1 매핑을 유지한다. UPDATE/DELETE 요청이 들어오면 비용 모델이 두 가지 경로(전체 재작성 vs. 어태치드에 delta 기록)를 비교한다. 비용 모델은 레코드 수정 비율, 파일 크기, HBase 쓰기 비용, 향후 컴팩션 비용 등을 정량화해 최적 경로를 선택한다.
읽기 연산은 UNION‑READ 단계에서 수행된다. Hive의 InputFormat이 마스터와 어태치드 데이터를 동시에 스트리밍하고, 동일 row‑id를 기준으로 최신 버전을 선택한다. 이 과정에서 HBase의 랜덤 읽기 특성을 활용해 필요한 delta만 빠르게 조회하므로, 전체 쿼리 성능에 큰 영향을 주지 않는다. 또한 일정 주기로 COMPACT 작업을 수행해 어태치드 테이블에 누적된 delta를 마스터 테이블에 병합하고, HBase에 남은 레코드를 정리한다. 이는 delta 폭증에 따른 조회 지연을 방지하고, 스토리지 비용을 절감한다.
시스템 구현 측면에서 DualTable은 Hive 메타스토어에 새로운 테이블 속성을 추가하고, 커스텀 StorageHandler와 SerDe를 통해 HDFS와 HBase를 동시에 관리한다. INSERT INTO와 CREATE TABLE은 기존 Hive와 동일하게 동작하지만, UPDATE·DELETE는 내부적으로 HBase에 put/delete를 수행한다. 또한, 기존 Hive‑ACID와 호환되도록 트랜잭션 로그와 스냅샷 메커니즘을 재활용한다.
실험 결과는 두 가지 워크로드를 사용한다. 첫 번째는 TPC‑H의 LINEITEM 테이블에 10 % 규모의 UPDATE/DELETE를 적용한 경우이며, 두 번째는 스마트 그리드에서 60 GB 규모의 전력 측정 데이터에 0.01 % 수준의 레코드 수정 작업을 수행한 경우이다. 두 시나리오 모두 DualTable은 순차 읽기 성능을 거의 유지하면서, UPDATE·DELETE 처리 시간을 기존 Hive 대비 6배~10배 단축하였다. 특히, 작은 비율의 수정이 빈번히 발생하는 스마트 그리드 환경에서 INSERT OVERWRITE 방식이 초래하는 I/O 폭증을 효과적으로 억제했다.
핵심 인사이트는 “읽기‑최적화와 쓰기‑최적화를 물리적으로 분리하되, 비용 모델을 통해 동적으로 선택한다”는 설계 철학이다. 이는 기존 Hive가 직면한 스토리지 구조의 트레이드오프를 근본적으로 해소하고, 대규모 배치 분석 플랫폼이 기업 수준의 복합 비즈니스 로직을 지원하도록 확장한다는 점에서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기