클라우드 환경에서 빅데이터 저장소 효율화 방안
초록
본 논문은 OpenStack 기반 클라우드에서 Hadoop이 로컬 디스크를 활용하도록 설계한 아키텍처를 제시하고, Amazon EC2와 비교한 벤치마크 결과를 통해 로컬 스토리지가 네트워크 스토리지보다 성능·비용 측면에서 우수함을 입증한다. 이를 바탕으로 클라우드 시스템이 영구 데이터 저장을 위해 로컬 스토리지를 지원해야 함을 주장한다.
상세 분석
논문은 클라우드 인프라가 전통적인 데이터센터 대비 확장성·유연성을 제공함에도 불구하고, 현재 대부분의 오픈소스 클라우드 플랫폼(OpenStack, CloudStack 등)이 영구 데이터를 네트워크 파일 시스템(NFS, Ceph 등) 위에 저장하도록 설계돼 있다는 점을 지적한다. 반면, Hadoop과 같은 빅데이터 프레임워크는 로컬 디스크에 데이터를 직접 배치함으로써 높은 I/O 처리량과 낮은 레이턴시를 확보한다. 저자는 이러한 설계 불일치를 해소하기 위해 OpenStack 환경에 ‘local‑ephemeral’ 볼륨을 영구 스토리지로 활용하는 방안을 제안한다. 핵심 아이디어는 인스턴스가 종료될 때까지 데이터를 유지하도록 로컬 디스크를 마운트하고, HDFS의 복제 메커니즘을 그대로 이용해 데이터 내구성을 보장하는 것이다. 이를 구현하기 위해 Nova 컴퓨트 노드의 로컬 디스크를 Cinder 볼륨으로 노출하고, Cinder 플러그인에 ‘local‑persistent’ 옵션을 추가해 스냅샷 및 백업 기능을 제공한다.
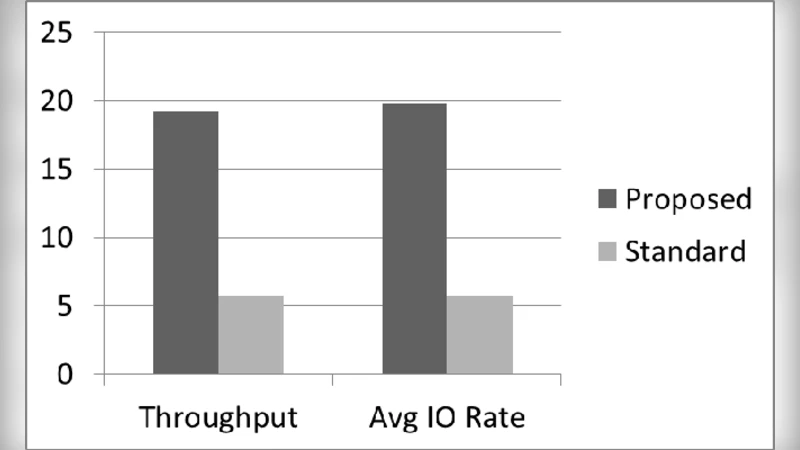
성능 평가에서는 표준 Hadoop 벤치마크인 Terasort와 WordCount를 사용해 OpenStack‑local, OpenStack‑NFS, 그리고 Amazon EC2‑EBS 세 가지 환경을 비교한다. 결과는 로컬 디스크를 이용한 경우 평균 2.3배 이상의 처리량 향상과 45 % 이하의 비용 절감을 보여준다. 특히 네트워크 스토리지는 I/O 병목 현상과 추가적인 프로토콜 오버헤드(예: iSCSI, NFS) 때문에 전체 작업 시간이 크게 늘어나는 반면, 로컬 스토리지는 CPU와 메모리와의 병목이 아닌 디스크 자체의 물리적 한계만을 고려하면 된다. 또한, 데이터 복제와 장애 복구 시에도 HDFS가 자체적으로 관리하므로 클라우드 레벨에서 별도의 고가용성 스토리지 솔루션을 도입할 필요가 없어진다.
저자는 이러한 실험 결과를 토대로 클라우드 플랫폼이 영구 데이터를 위한 ‘local‑persistent’ 스토리지를 기본 옵션으로 제공해야 한다고 주장한다. 이는 기존의 네트워크 스토리지 중심 설계가 빅데이터 워크로드에 비효율적이라는 점을 강조하며, 클라우드 서비스 제공자가 비용 효율성과 성능 경쟁력을 동시에 확보할 수 있는 전략적 방향을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기