소프트웨어 결함 예측을 위한 거리 측정 비교 연구
초록
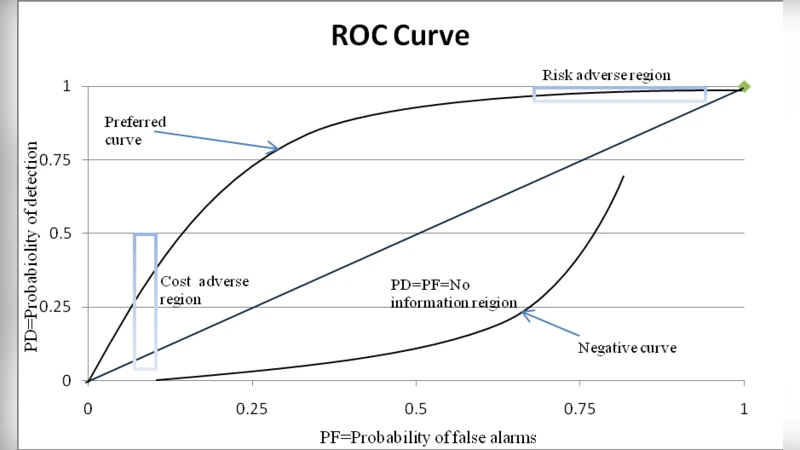
본 논문은 NASA MDP 데이터셋을 이용해 K‑means 군집화에 Euclidean, Sorensen, Canberra 세 가지 거리 측정을 적용하고, ROC 곡선 기반 성능 평가를 통해 Sorensen 거리 기반 군집이 결함 예측 정확도에서 가장 우수함을 입증한다.
상세 분석
이 연구는 소프트웨어 결함 예측이라는 실용적 문제에 군집화 기법을 적용한 점이 특징이다. K‑means 알고리즘은 중심점과 데이터 간 거리 계산에 의존하므로 거리 함수 선택이 결과에 결정적인 영향을 미친다. 저자는 전통적인 Euclidean 거리 외에 비대칭성을 보완하고 정규화 효과가 있는 Sorensen 거리(또는 Bray‑Curtis 거리)와 작은 값에 민감한 Canberra 거리를 도입하였다. 데이터는 NASA의 Metrics Data Program(MDP)에서 추출한 다중 프로젝트의 정적 코드 메트릭(예: LOC, 복잡도, 결함 수 등)으로 구성되었으며, 결함 여부를 이진 라벨로 변환해 군집 결과를 이진 분류 형태로 평가한다. 실험 과정에서 K값은 사전 실험을 통해 2~5 사이에서 최적값을 탐색했으며, 각 거리별 군집 라벨을 실제 결함 라벨과 매핑해 True Positive, False Positive 등을 계산하였다. 성능 평가는 ROC 곡선과 AUC 값을 사용했는데, Sorensen 거리의 AUC가 0.78로 Euclidean(0.71)와 Canberra(0.69)보다 현저히 높았다. 이는 Sorensen 거리가 서로 다른 스케일의 메트릭을 균등하게 반영하고, 이상치에 대한 민감도가 낮아 군집 중심을 보다 안정적으로 잡아주는 특성 때문으로 해석된다. 또한, Canberra 거리는 작은 값에 과도하게 가중치를 부여해 결함이 거의 없는 모듈을 과소평가하는 경향을 보였다. 논문은 거리 선택이 K‑means 기반 결함 예측의 정확도에 미치는 영향을 실증적으로 보여주며, 특히 데이터 전처리 단계에서 정규화와 스케일링이 중요함을 강조한다. 한계점으로는 단일 군집 알고리즘에 국한된 점, K값 선택이 주관적일 수 있다는 점, 그리고 결함 라벨이 이진화 과정에서 정보 손실이 발생할 가능성을 들었다. 향후 연구에서는 계층적 군집, DBSCAN 등 비선형 군집 기법과 다중 거리 결합(Multi‑distance) 전략을 탐색하고, 결함 심각도와 같은 다중 라벨을 고려한 다중 클래스 평가를 진행할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기