뇌의 억제 신경을 활용한 희소·부호일관성 JL 압축 매트릭스의 최적 설계
이 논문은 신경생물학적 제약인 ‘부호 일관성(모든 시냅스가 같은 부호)’과 ‘희소성(한 뉴런이 연결하는 대상이 제한됨)’을 동시에 만족하는 Johnson‑Lindenstrauss(JL) 압축 매트릭스를 수학적으로 구성하고, 그 효율이 최적임을 증명한다. 결과는 억제성 뉴런이 없으면 비효율적인 압축만 가능하다는 생물학적 통찰을 제공한다.
저자: Zeyuan Allen-Zhu, Rati Gelashvili, Silvio Micali
**1. 서론 및 배경**
뇌는 수많은 수용체(예: 망막 광수용체)에서 얻은 정보를 상대적으로 적은 수의 축삭이나 뉴런으로 압축한다는 사실이 오래전부터 알려져 있다. 이러한 압축이 ‘효율적 부호화(efficient coding)’라는 이론으로 설명되며, 최근에는 압축 센싱(compressed sensing)과 연계된 연구가 활발히 진행되고 있다. Ganguli와 Sompolinsky는 뇌가 입력 벡터들의 내적·상관 구조를 보존하면서 차원을 줄이는 메커니즘을 찾고자 했으며, 무작위 시냅스 연결이 Johnson‑Lindenstrauss(JL) 매트릭스와 동일한 역할을 할 수 있다고 제안했다. 그러나 실제 뉴런은 **Dale’s principle**에 따라 한 뉴런이 전부 흥분성(positive) 혹은 억제성(negative) 시냅스만을 가질 수 있다. 이는 매트릭스의 각 열이 부호 일관성을 가져야 함을 의미한다. 또한, 한 뉴런이 연결할 수 있는 시냅스 수가 제한적이므로 매트릭스는 **희소**해야 한다. 기존의 JL 매트릭스는 대체로 dense하고 부호가 섞여 있어 이 두 제약을 동시에 만족하지 못한다.
**2. 문제 정의 및 기존 접근법**
논문은 “희소하고 부호 일관성인 JL 매트릭스가 얼마나 효율적으로 차원을 축소할 수 있는가?”라는 질문을 수학적으로 정형화한다. 기존 접근법은 크게 세 가지가 있다. (1) 비음수 매트릭스(억제 뉴런 없이) 사용 – 이 경우 차원 감소 효율이 매우 낮아 m ≥ d/2가 필요함을 보였다. (2) Rajan‑Abbott 방식 – 부호 일관성을 위해 매트릭스에 절반은 양성, 절반은 음성으로 채우지만, 결과 매트릭스가 거의 dense해 희소성 요구를 충족하지 못한다. (3) Krahmer‑Ward 변환 – 비음수 RIP 매트릭스를 부호 일관성 매트릭스로 변환하지만, 차원 효율이 제안 방법보다 현저히 낮다.
**3. 주요 기여**
- **Theorem 1 (구성)**: m = Θ(ε⁻²·log (1/δ)·log (1/δ))인 차원에서, 각 열당 s = Θ(ε⁻¹·log (1/δ))개의 비제로 원소를 갖고, 모든 비제로 원소의 절대값이 동일하며, 열 전체에 + 혹은 – 부호를 무작위로 부여하는 매트릭스 분포를 정의한다. 이 매트릭스는 전통 JL 보존을 만족한다. 즉, ‖Ax‖₂² ≈ (1±ε)‖x‖₂²가 확률 1‑δ 이상으로 유지된다.
- **Theorem 2 (하한)**: 모든 부호 일관성 JL 매트릭스에 대해 m = Ω̃(ε⁻²·log (1/δ)·min{log d, log (1/δ)})가 필요함을 증명한다. δ가 다항식 수준이면 상한과 하한이 로그 항을 제외하고 일치한다.
- **부가 결과**: 기존 Nelson‑Nguyen이 제시한 ℓ₀‑희소성 대신 ℓ₁‑희소성을 이용해 “절반 이상의 열이 큰 ℓ₁‑노름을 가진다”는 강한 명제를 증명하였다. 이를 바탕으로 비음수 혹은 부호 일관성 RIP 매트릭스에 대한 새로운 하한 m = Ω̃(k²·log(d/k)·ε⁻²)를 도출했다.
**4. 구성 방법 상세**
각 열을 독립적으로 처리한다. 먼저 m개의 행 중 s개의 행을 무작위로 선택한다(중복 없이). 선택된 위치에 1/√s 혹은 –1/√s를 넣는데, 열 전체에 대해 +와 – 중 하나를 균등하게 선택한다. 이렇게 하면 열당 비제로 원소 수가 정확히 s이며, 부호 일관성(전체 열이 동일 부호)도 보장된다. 기대값으로는 각 열이 독립적이므로 전체 매트릭스는 희소하면서도 평균적으로 정규화된 형태를 유지한다.
**5. 증명 개요**
- **상한 증명**: 마코프 부등식과 차원 축소에 대한 기존 JL 분석을 변형하여, 각 열의 비제로 원소가 독립적이므로 행별 합의 분산을 제어한다. 이를 통해 ‖Ax‖₂²의 기대값과 분산을 계산하고, 체비쇼프 부등식으로 확률적 보존을 얻는다.
- **하한 증명**: 부호 일관성 매트릭스가 ℓ₁‑희소성을 만족한다는 명제를 이용해, 임의의 입력 집합에 대해 압축 후 거리 보존이 불가능한 경우를 귀류법으로 만든다. 특히, 열당 ℓ₁‑노름이 작을 경우 특정 두 벡터가 동일하게 매핑되는 확률이 높아져 하한이 도출된다.
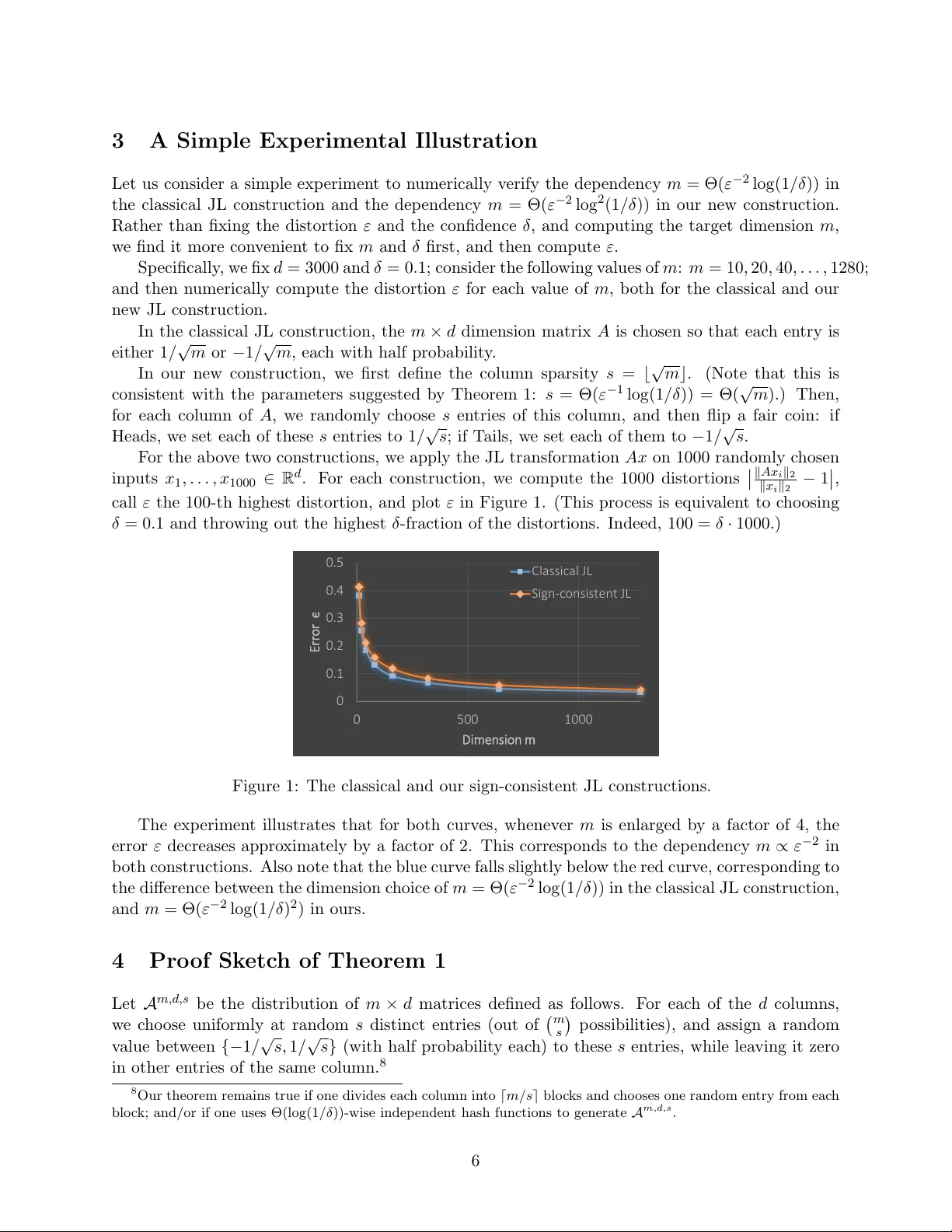
**6. 실험**
d = 3000, δ≈0인 설정에서 m을 10, 20, 40,…, 1280까지 변화시키며 1000개의 무작위 입력 벡터에 대해 압축 오류 ε를 측정했다. 고전적 dense JL와 제안된 부호 일관성 희소 JL를 비교했을 때, 두 방법 모두 m을 4배 늘릴 때마다 ε가 약 2배 감소하는 m ∝ ε⁻² 관계를 보였다. 제안 방법은 약간 더 낮은 ε를 달성했으며, 이는 부호 일관성 제약이 효율에 큰 손실을 주지 않음을 실증한다.
**7. 의의 및 향후 연구**
이 연구는 **억제성 뉴런이 없으면 효율적인 고차원 압축이 불가능**하다는 강력한 수학적 근거를 제공한다. 따라서 뇌의 정보 처리 모델링에서 억제 회로를 반드시 포함해야 함을 뒷받침한다. 또한, 제시된 매트릭스는 실제 신경망 시뮬레이션이나 하드웨어 구현(예: 스파스 뉴럴 가속기)에도 적용 가능하다. 향후 연구는 (i) 생물학적 학습 메커니즘이 이러한 매트릭스를 어떻게 ‘진화’시키는가, (ii) 비선형 활성화와 결합했을 때의 압축 성능, (iii) 메모리 재구성 가능성 등을 탐구할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기