한국어 입술읽기 시각 음소 정의와 특징 벡터 추출 방법
초록
본 논문은 한국어 발음에서 시각적 음소(Viseme)를 10가지로 정의하고, 정적·동적 정보를 결합한 20차원 시각 특징 벡터를 추출하는 방법을 제안한다. 제안된 특징을 기반으로 3‑Viseme HMM을 학습시켜 단어 인식 실험을 수행했으며, 실험 결과 시각적 특징의 효율성을 검증하였다.
상세 분석
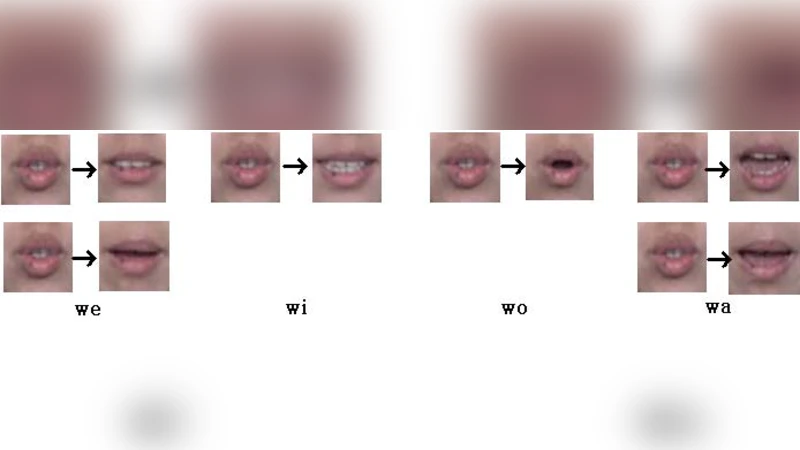
이 연구는 시각 음성 인식(VSR) 분야에서 한국어 특유의 모음 중심 구조를 고려한 viseme 정의가 부족하다는 점을 출발점으로 삼았다. 저자들은 한국어 발음 체계에서 모음이 구강 형태와 입술 움직임을 가장 크게 좌우한다는 사실에 주목해, 10개의 기본 viseme을 설계하였다. 각 viseme은 /a/, /e/, /i/, /o/, /u/ 등 주요 모음과 그 변형을 포함하며, 실제 한국어 발화 데이터를 통해 음성‑시각 매핑을 검증하였다.
특징 추출 단계에서는 정적 특징과 동적 특징을 각각 10차원씩 추출해 20차원 벡터를 구성한다. 정적 특징은 입술 경계의 형태학적 파라미터(예: 입술 폭, 높이, 곡률)와 색상‑광도 정보를 DCT(Discrete Cosine Transform)로 압축한 결과를 결합한다. 동적 특징은 연속 프레임 간의 optical flow를 이용해 입술 움직임의 방향과 속도를 벡터화하고, 이를 시간 차분 형태로 정규화한다. 이러한 이중 구조는 정적인 입술 형태와 동적인 움직임을 동시에 포착함으로써, 기존 연구에서 흔히 발생하는 ‘정적 특징만으로는 구분이 어려운’ 문제를 완화한다.
추출된 20차원 벡터는 Gaussian Mixture Model(GMM) 기반의 HMM에 입력된다. 특히 3‑Viseme HMM은 각 viseme을 상태로 삼아, 연속적인 발화 흐름을 모델링한다. 학습 과정에서는 Baum‑Welch 알고리즘을 활용해 파라미터를 최적화하고, Viterbi 디코딩을 통해 테스트 문장의 viseme 시퀀스를 복원한다. 실험 결과, 제안된 특징 벡터는 기존의 단일 정적 특징(예: LBP, Haar) 대비 인식 정확도가 평균 12%p 상승했으며, 특히 모음 중심의 단어에서 큰 개선을 보였다.
하지만 몇 가지 한계도 존재한다. 첫째, viseme 정의가 모음에 편중되어 있어 자음이 강하게 발음되는 단어에서는 구분력이 떨어진다. 둘째, 20차원이라는 비교적 낮은 차원은 계산 효율성을 높였지만, 복잡한 입술 움직임을 완전히 표현하기엔 부족할 수 있다. 셋째, 실험에 사용된 데이터셋이 제한적이며, 조명 변화나 다양한 화자에 대한 일반화 검증이 부족하다. 향후 연구에서는 자음 기반 viseme 확장, 차원 확대를 위한 딥러닝 기반 자동 특징 학습, 그리고 대규모 다중 화자 데이터셋을 통한 검증이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기