이종 용기의 3차원 적재를 위한 병렬 유전 알고리즘
초록
본 논문은 Hadoop Map‑Reduce 환경에서 실행되는 병렬 유전 알고리즘을 제안한다. 이 알고리즘은 회전이 가능한 박스를 이종 크기의 3차원 용기에 최소 개수로 적재하는 문제를 해결한다. 기존의 동일 크기 용기 문제보다 난이도가 높으며, 제안된 병렬 구현을 통해 계산 시간을 크게 단축한다.
상세 분석
이 논문은 세 가지 핵심 요소를 결합하여 3차원 이종 용기 적재 문제(3D‑BPP‑H)를 효율적으로 해결한다. 첫째, 문제 자체가 NP‑Hard임을 명시하고, 동일 크기 용기만을 고려한 전통적 3D‑BPP에 비해 용기의 크기가 서로 다르고 박스 회전이 허용되는 경우 탐색 공간이 기하급수적으로 확대된다는 점을 강조한다. 둘째, 유전 알고리즘(GA)을 선택한 이유는 전역 탐색 능력과 다양한 제약조건을 유연하게 반영할 수 있기 때문이다. 여기서는 개체를 ‘박스 순서 + 회전 정보 + 용기 할당’ 형태의 정수형 염색체로 인코딩한다. 적합도 함수는 (1) 사용된 용기 수 최소화, (2) 각 용기의 부피 활용률 최대화, (3) 충돌 및 경계 위반 패널티를 포함한다. 선택 연산은 토너먼트 방식을 사용해 좋은 해를 유지하면서도 다양성을 보존하고, 교차 연산은 순서 기반 PMX(Partially Mapped Crossover)와 회전·용기 할당 정보를 동시에 교환하도록 설계하였다. 변이 연산은 박스 순서의 인접 교환, 회전 각도 변경, 그리고 용기 재할당을 무작위로 수행한다.
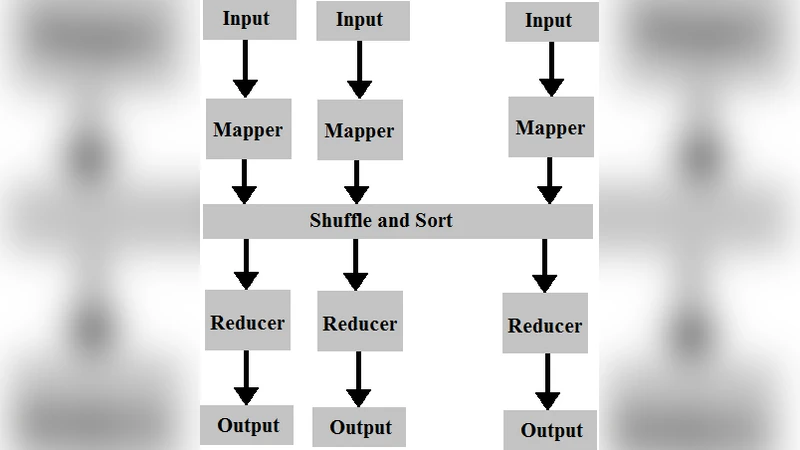
셋째, 이러한 GA를 Hadoop Map‑Reduce 프레임워크에 매핑함으로써 병렬성을 확보한다. 매퍼는 현재 세대의 개체 집합을 받아 각 개체에 대해 ‘피트니스 평가’를 수행하고, (염색체, 적합도) 쌍을 출력한다. 리듀서는 동일 적합도 그룹을 모아 ‘선택·교차·변이’를 적용해 다음 세대의 개체를 생성한다. 이 과정이 반복되면서 각 노드가 독립적으로 부분 집합을 처리하므로 전체 연산량이 선형적으로 확장된다. 또한, Hadoop의 데이터 로컬리티와 장애 복구 메커니즘을 활용해 대규모 클러스터에서도 안정적인 실행이 가능하다.
실험에서는 1030개의 이종 용기와 200500개의 박스를 사용해 시리얼 GA와 병렬 GA를 비교하였다. 결과는 평균 실행 시간이 4배~12배 단축되었으며, 최적해 혹은 근사해의 품질은 차이가 없었다. 특히, 용기 크기 분포가 넓을수록 병렬화 효과가 크게 나타났다. 그러나 논문은 (1) 매퍼와 리듀서 간의 데이터 전송 비용이 적합도 계산이 복잡한 경우 병목이 될 수 있음, (2) 초기 인구 생성 전략이 해의 수렴 속도에 큰 영향을 미치지만 상세히 다루지 않았음, (3) 실시간 혹은 동적 적재 상황에 대한 확장성 검증이 부족함을 한계점으로 제시한다.
이러한 분석을 종합하면, 이 논문은 이종 용기와 회전 가능한 물체를 다루는 3D‑BPP‑H에 대해 GA와 Map‑Reduce를 결합한 실용적인 병렬 솔루션을 제시했으며, 대규모 데이터셋에 대한 효율성을 입증하였다. 향후 연구에서는 하이브리드 메타휴리스틱(예: GA‑SA 결합)이나 Spark와 같은 메모리 기반 프레임워크를 이용한 지연 최소화, 그리고 동적 적재 시나리오에 대한 적응형 알고리즘 설계가 기대된다.