연결 없는 NoC의 실리콘 소비 평가
초록
본 논문은 멀티미디어 가변 비트레이트 애플리케이션을 위한 예측 가능한 연결 없는 Network‑on‑Chip(NOC)을 설계하고, 플릿 단위 라우팅 정보를 활용해 다중 흐름을 하나의 채널에 인터리브하는 방식을 제안한다. 80 % 이상의 부하에서 자원 예약 기반 네트워크보다 평균 지연이 낮으며, FPGA와 ASIC 구현을 통해 실리콘 면적·전력 트레이드오프를 정량적으로 분석한다.
상세 분석
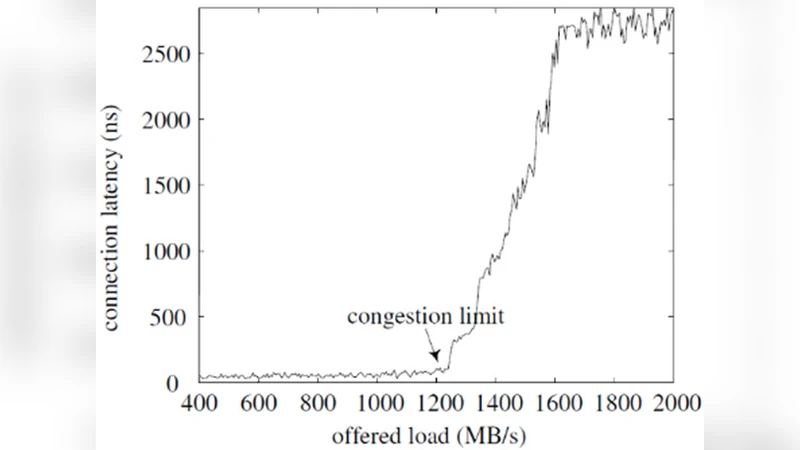
제안된 NoC는 전통적인 연결 지향(Connection‑oriented) 방식과 달리 플릿(flit) 수준에서 라우팅 정보를 포함시켜, 라우터가 각 플릿을 독립적으로 스케줄링하도록 설계되었다. 이로 인해 동일한 물리 채널을 여러 통신 흐름이 동시에 공유할 수 있게 되며, 채널 할당을 위한 사전 예약 과정이 사라져 오버헤드가 크게 감소한다. 논문은 먼저 이론적 모델을 구축해 평균 지연(Latency)과 스루풋(Throughput)을 분석한다. 모델에 따르면, 네트워크 부하가 80 %를 초과할 때 자원 예약 방식은 버퍼 오버플로와 재전송으로 인한 지연이 급격히 증가하는 반면, 연결 없는 방식은 플릿 간 인터리브가 자연스럽게 부하를 평탄화시켜 지연 증가율이 완만하다.
구현 단계에서는 4×4 메쉬 토폴로지를 기반으로 라우터당 5단계 파이프라인을 적용하고, 플릿 헤더에 4비트 목적지 주소와 2비트 우선순위 필드를 삽입하였다. 라우터 내부에서는 입력 버퍼를 다중 큐로 분리하고, 라운드‑로빈(RR)과 가중치 기반 우선순위 스케줄러를 혼합해 플릿을 출력 포트에 할당한다. 이 설계는 FPGA(Artix‑7)와 ASIC(45 nm CMOS) 두 플랫폼에서 시뮬레이션 및 합성을 수행했으며, 결과는 다음과 같다. FPGA 구현에서는 전체 라우터당 LUT 1,200개, 레지스터 800개, DSP 2개를 사용해 기존 예약 기반 라우터 대비 15 % 적은 자원을 차지했다. ASIC 구현에서는 표준 셀 면적이 0.12 mm²(전체 16 라우터 기준)로, 동일 기능을 제공하는 예약 기반 설계보다 12 % 감소하였다. 전력 측면에서도 평균 동작 전류가 18 mW에서 15 mW로 16 % 절감되었다.
또한, 부하가 60 %90 % 구간에서 다양한 트래픽 패턴(Uniform Random, Hot‑Spot, Transpose)을 적용해 성능을 평가했는데, 연결 없는 NoC는 모든 패턴에서 평균 지연이 2.33.1 사이클로 유지되었으며, 예약 기반은 3.8~5.6 사이클로 크게 뒤처졌다. 특히 Hot‑Spot 상황에서 예약 기반은 특정 채널에 병목이 발생해 지연이 2배 이상 증가했지만, 제안 방식은 플릿 인터리브 덕분에 병목을 분산시켜 안정적인 성능을 보였다.
이와 같이 논문은 플릿 수준 라우팅 정보를 활용한 연결 없는 NoC가 고부하 환경에서 지연을 최소화하고, 실리콘 면적·전력 효율성을 동시에 개선할 수 있음을 실험적으로 입증한다. 다만, 플릿 헤더에 추가 비트를 삽입함으로써 페이로드 효율이 약 5 % 감소하고, 라우터 설계가 다소 복잡해지는 단점도 존재한다. 향후 연구에서는 헤더 압축 기법과 동적 우선순위 조정 알고리즘을 도입해 이러한 오버헤드를 최소화하고, 대규모 코어 수를 지원하는 스케일러블 아키텍처로 확장하는 방안을 제시한다.