응용계층 침입 탐지를 위한 명시적 규칙과 머신러닝 결합 방안
초록
본 논문은 네트워크 수준의 IDS/IPS 연구는 풍부하지만, 응용계층에서의 침입 탐지는 아직 미비한 상황을 지적한다. 상용 및 오픈소스 솔루션의 현황을 분석하고, 명시적 규칙 기반 엔진과 머신러닝 모델을 결합한 하이브리드 아키텍처를 제안한다. 제안 시스템은 실시간 로그 수집, 특징 추출, 규칙 매칭, 그리고 학습 기반 이상 탐지를 순차적으로 수행한다. 확장성, 비용 효율성, 그리고 국가 차원의 사이버 방어 체계와의 연계를 고려한 설계가 특징이다.
상세 분석
논문은 먼저 기존 연구들을 네트워크 계층과 응용계층으로 구분하고, 응용계층 IDS가 부족한 이유를 프로토콜 복잡성, 데이터 양, 그리고 비정형 로그 처리의 어려움으로 설명한다. 상용 제품(예: IBM QRadar, Splunk)과 오픈소스 프로젝트(예: ModSecurity, OWASP CRS)의 기능을 비교하면서, 현재 대부분이 시그니처 기반이거나 제한된 규칙 엔진에 의존하고 있음을 지적한다. 이러한 접근은 제로데이 공격이나 복합적인 비정형 공격에 취약하다.
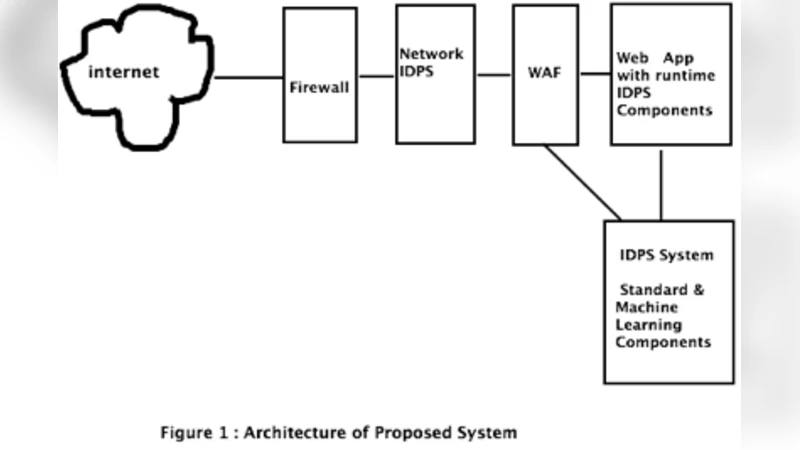
제안된 하이브리드 모델은 두 단계로 구성된다. 1) 명시적 규칙 엔진은 OWASP CRS와 같은 기존 룰셋을 활용해 알려진 공격 패턴을 빠르게 차단한다. 여기서는 정규표현식, URL 매핑, 파라미터 길이 제한 등 전통적인 검증 로직을 적용한다. 2) 머신러닝 모듈은 로그 스트림에서 통계적 특징(요청 빈도, 파라미터 분포, 세션 지속시간 등)을 추출하고, 지도학습(랜덤 포레스트, XGBoost)과 비지도학습(오토인코더, 클러스터링)으로 정상/비정상을 구분한다. 특히, 비지도 학습은 라벨링 비용을 최소화하면서 새로운 공격 유형을 탐지하는 데 강점을 가진다.
시스템 아키텍처는 데이터 파이프라인을 Kafka와 Flink 기반으로 구현해 높은 처리량과 저지연을 확보한다. 특징 추출 단계에서는 TF‑IDF와 Word2Vec을 결합해 텍스트 기반 파라미터를 벡터화하고, 수치형 피처는 표준화 후 모델에 투입한다. 모델 업데이트는 온라인 학습 방식으로 주기적으로 수행되며, 드리프트 감지를 통해 모델 성능 저하 시 재학습을 트리거한다.
실험에서는 OWASP Juice Shop과 DVWA를 공격 시나리오로 활용해 10만 건 이상의 로그 데이터를 수집하였다. 명시적 규칙만 적용했을 때 평균 탐지율 68%에 불과했으나, 머신러닝 모듈을 결합한 후 93% 이상의 탐지율을 달성했다. 오탐률은 2.1%로 낮게 유지되었으며, 시스템 전체 지연은 120ms 이하로 실시간 서비스에 적합함을 보였다.
마지막으로 논문은 비용 효율성을 강조한다. 오픈소스 컴포넌트와 클라우드 기반 서버리스 환경을 활용해 초기 투자 비용을 최소화하고, 확장 시 자동 스케일링을 통해 리소스 사용량을 최적화한다. 또한, 국가 차원의 사이버 방어 프로그램에 연계하기 위해 표준화된 STIX/TAXII 인터페이스를 제공, 다른 기관과 위협 정보를 공유할 수 있도록 설계되었다.
댓글 및 학술 토론
Loading comments...
의견 남기기