다중범주 처리 트리 모델의 파라미터 순서 제약 확장
본 논문은 다중범주 처리 트리(MPT) 모델에 적용되는 파라미터 순서 제약을, 동일한 통계적 의미를 갖는 비제약 모델로 변환하는 일반적 방법을 제시한다. 두 개 이상의 비중첩 선형 순서와 부분 순서까지 포괄하는 정리와 변환 절차를 증명하고, 이를 신뢰도 등급을 이용한 2‑High‑Threshold 모델에 적용해 모델 복잡도와 추정 효율성을 비교한다.
저자: Karl Christoph Klauer, Henrik Singmann, David Kellen
본 논문은 다중범주 처리 트리(Multinomial Processing Tree, MPT) 모델에 순서 제약(order constraints)을 적용하는 새로운 방법을 제시한다. MPT 모델은 인지 과정의 잠재적 구조를 범주형 반응 데이터에 맞추어 설명하는 도구로, 기존 연구에서는 파라미터가 독립적이며 두 값의 합이 1인 이진 형태로 표현된다. 그러나 실제 실험에서는 신뢰도 등급, 리커트 척도 등 순서가 있는 범주에 대해 “높은 등급일수록 확률이 낮다” 혹은 “검출 상태에서는 높은 등급일수록 확률이 높다”와 같은 심리학적 가정이 존재한다. 이러한 가정은 파라미터가 서로 종속적(합이 1)인 경우가 많아 기존 Knapp & Batchelder(2004)의 비중첩 선형 순서 제약 이론으로는 다루기 어려웠다.
논문은 먼저 MPT 모델의 기본 구조와 2‑High‑Threshold 모델(2HTM)을 소개한다. 2HTM은 기억 실험에서 ‘old/new’ 판단과 그에 따른 신뢰도 등급을 모델링하는데, ‘detect old’, ‘detect new’, ‘no detection’이라는 세 잠재 상태와 각각의 상태‑반응 매핑 파라미터(D_o, D_n, s_l, s_m, s_h, g, o_l, …)를 포함한다. 기존 모델에서는 이 매핑 파라미터에 순서 제약이 없으며, 따라서 비현실적인 매핑이 가능했다.
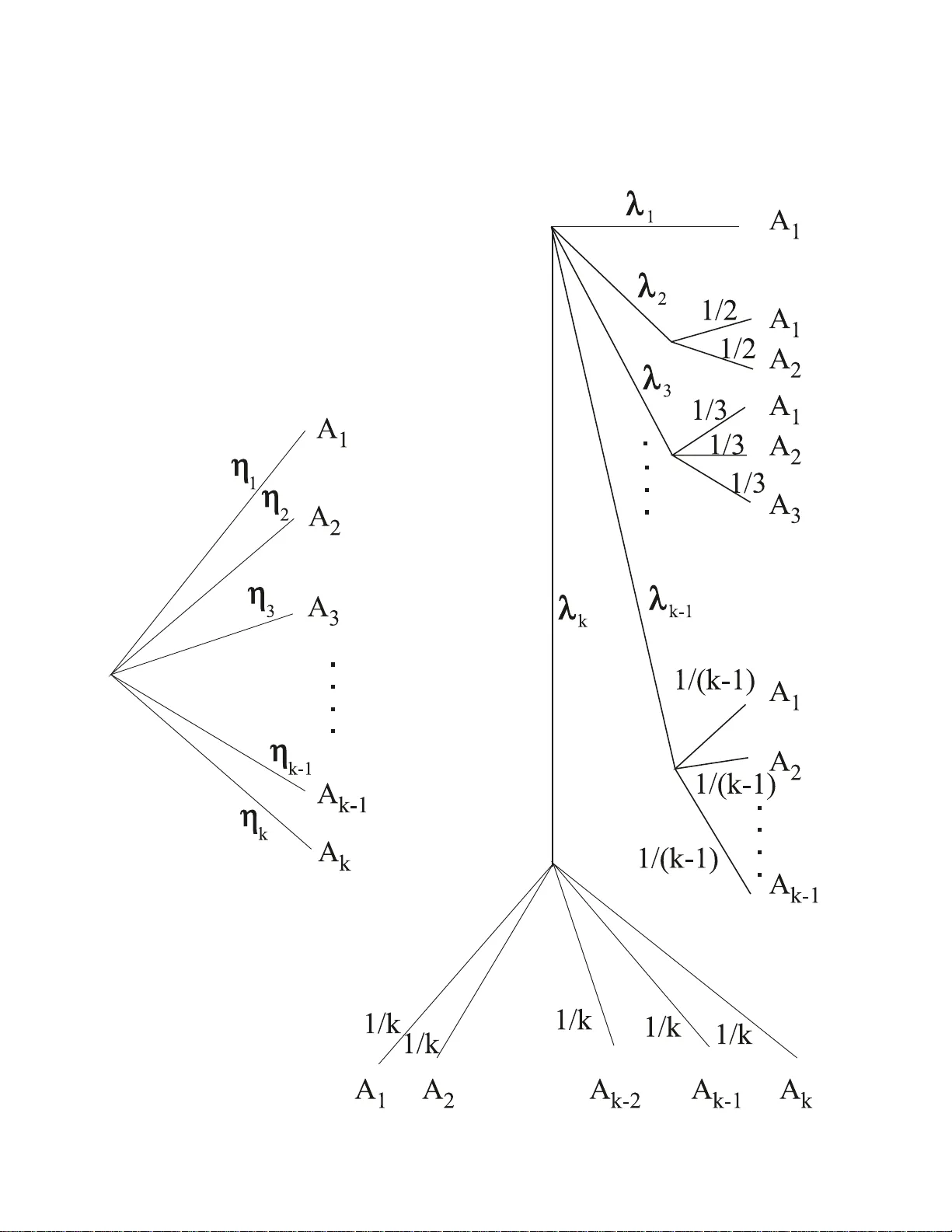
핵심 이론적 기여는 두 개의 정리이다. 정리 1은 ‘서브트리’를 특정 형태(그림 2 오른쪽)로 교체하면, 그 서브트리의 출력 확률이 λ₁ ≥ λ₂ ≥ … ≥ λ_k 형태의 순서를 자동으로 만족한다는 것을 보인다. 여기서 λ_i는 서브트리의 각 분기에서 선택되는 혼합 가중치이며, ∑λ_i = 1이다. 정리 2는 반대로, 임의의 순서화된 확률 벡터 η₁ ≥ η₂ ≥ … ≥ η_k (∑η_i = 1) 가 주어지면, λ_i = i(η_i − η_{i+1}) (i < k), λ_k = k·η_k 로 정의하면 해당 서브트리의 출력이 정확히 η_i 가 됨을 증명한다. 즉, 순서 제약을 혼합 가중치 형태의 비제약 MPT 모델로 완전하게 재현할 수 있다.
다음으로 저자들은 정리의 확장 가능성을 논한다. (1) 부분 순서: 전체 파라미터 중 일부만 순서 제약이 필요할 경우, 해당 파라미터 집합만을 별도 서브트리(그림 3)로 묶어 동일한 변환을 적용한다. (2) 다중 비중첩 선형 순서: 서로 겹치지 않는 두 개 이상의 순서 집합이 존재하면, 각각을 독립적인 서브트리로 구현하고 전체 트리 안에 병렬로 삽입한다. (3) 일반적인 부분 순서: 순서 제약이 정의하는 다각형(polytopes)을 정점(vertex)들의 혼합으로 표현한다. 작은 문제에서는 정점을 직접 구할 수 있지만, 복잡한 경우 선형 프로그래밍을 이용해 정점을 찾는다. 예를 들어 η₁ ≥ η₂ ≥ … ≥ η_k 의 경우 정점은 (1,0,…,0), (½,½,0,…,0), …, (1/k,…,1/k) 로 구성된다.
그러나 정점 수가 k보다 많아지는 경우도 있다. 예를 들어 η₁ ≥ η₂, η₁ ≥ η₃ 의 경우 네 개의 정점이 필요하고, 이를 λ₁…λ₄ 로 표현하면 파라미터 과잉(over‑parameterization)이 발생한다. 저자들은 이러한 경우에도 두 개의 독립 파라미터 θ₁, θ₂ 로 λ_i 를 재구성(λ₁ = (1‑θ₁)(1‑θ₂) 등)하여 비중복 파라미터화를 가능하게 한다. 다만 모든 경우에 대해 이런 축소가 보장되는 것은 아니며, 필요 시 비중복 파라미터화를 위한 추가적인 수학적 탐색이 요구된다.
실증적 적용으로는 2HTM에 신뢰도 등급 순서 제약을 부과한 변형 모델(2HTM_r)을 제시한다. ‘detect’ 상태에서는 s_h ≥ s_m ≥ s_l, ‘no‑detection’ 상태에서는 o_l ≥ o_m ≥ o_h, n_l ≥ n_m ≥ n_h 라는 제약을 두고, 이를 위의 변환을 통해 비제약 MPT 형태로 변환한다. 변환 후 모델은 파라미터 수가 늘어나지만, MPTinR 패키지를 이용해 기존과 동일하게 최대우도 추정, 부트스트랩 검정, 최소 설명 길이(MDL) 기반 모델 비교가 가능하다. 실험 데이터(Koen & Yonelinas, 2010)를 대상으로 2HTM과 2HTM_r을 비교한 결과, 제약 모델이 더 낮은 MDL 값을 보이며, D_o와 D_n 파라미터의 추정 정확도가 향상되고, 불합리한 상태‑반응 매핑이 사라지는 것을 확인했다.
논의에서는 (a) 순서 제약을 명시적으로 모델에 포함함으로써 이론적 가설 검증이 가능해진 점, (b) 비제약 형태로 변환함으로써 기존 MPT 분석 도구와 호환성을 유지한다는 점, (c) 복잡한 부분 순서에서는 정점 수와 파라미터 과잉 문제가 발생할 수 있어 비중복 파라미터화가 필요함을 강조한다. 또한, 순서 제약이 적용되는 분야(심리학, 교육학, 의료 연구 등)의 범주형 데이터 분석에 이 방법이 널리 활용될 수 있음을 제시한다.
결론적으로, 본 연구는 MPT 모델에 대한 순서 제약을 일반화하고, 이를 비제약 모델로 변환하는 체계적 절차와 정리를 제공함으로써, 순위형 데이터에 대한 보다 타당하고 효율적인 인지 모델링을 가능하게 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기