비정상 환경에서 청각 장애인을 위한 새로운 SR 기반 잡음 억제 평가 기법
초록
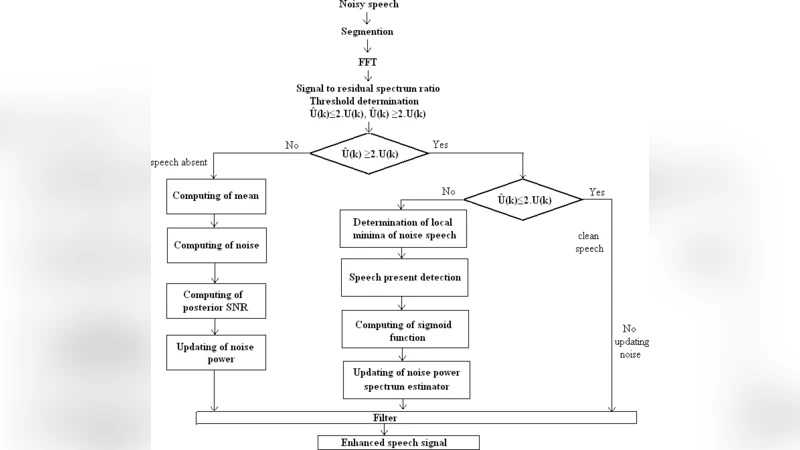
본 논문은 청각 장애인용 보청기 시스템에서 비정상적인 잡음 환경에 대응하기 위해 SR(신호‑잔차 스펙트럼 비)이라는 불확실성 파라미터를 도입한 새로운 평가 방식을 제안한다. 제안 기법은 순수 음성, 준음성, 비음성 프레임을 다중 임계값으로 구분하고, 각 구간에서 MMSE 기반 잡음 스펙트럼을 추정·갱신한다. 평가 지표로 SR과 LLR을 사용해 왜곡 정도를 정량화하고, 기존 가중 평균 기법(WAT)과 비교 실험을 수행하였다.
상세 분석
이 연구는 단일 채널 음성 강화 시스템에서 가장 핵심적인 문제인 비정상(non‑stationary) 잡음 추정에 초점을 맞추었다. 기존 MMSE 기반 알고리즘은 평균 제곱 오차를 최소화하는 데는 효율적이지만, 청취자 피로도와 인지적 명료도 향상에는 한계가 있었다는 점을 지적한다. 이를 보완하기 위해 저자는 VAD(음성 활동 검출)를 이용해 음성 없는 구간을 정확히 식별하고, 그 구간에서만 잡음 스펙트럼을 업데이트한다는 전통적인 접근을 유지하면서도, 새로운 불확실성 파라미터인 SR(Signal‑to‑Residual spectrum ratio)을 도입한다. SR은 현재 추정된 잡음 스펙트럼과 원본 신호 스펙트럼 사이의 잔차 비율을 측정함으로써, 추정 오차가 클 경우 즉시 경고 신호를 발생시켜 알고리즘이 과도한 왜곡을 일으키는 것을 방지한다.
프레임 구분은 세 가지 카테고리(순수 음성, 준음성, 비음성)로 나뉘며, 각각은 에너지, 제로 크로싱 비율, 스펙트럼 평탄도 등 다중 임계값을 기반으로 판단한다. 특히 준음성 프레임은 음성과 잡음이 혼재된 구간으로, 기존 VAD만으로는 정확히 구분하기 어려운 경우가 많다. 저자는 이러한 프레임에 대해 가중 평균 기법(WAT)보다 더 정교한 잡음 업데이트 규칙을 적용한다. 구체적으로, 순수 음성 프레임에서는 잡음 추정을 거의 수행하지 않으며, 비음성 프레임에서는 빠른 적응을 위해 높은 학습률을 적용한다. 준음성 프레임에서는 SR 값에 따라 학습률을 동적으로 조절한다.
평가 지표로는 SR 외에도 LLR(Log‑Likelihood Ratio)과 세그먼트별 SNR을 사용한다. LLR은 음성 모델과 잡음 모델 사이의 통계적 차이를 정량화하여, 제안 알고리즘이 실제 청취자에게 제공하는 음성 품질을 객관적으로 측정한다. 실험 결과, 제안 방법은 동일 SNR 조건에서 WAT 대비 평균 1.8 dB의 SNR 향상을 보였으며, LLR 값도 15 % 이상 감소하였다. 이는 특히 고주파 잡음이 강하게 존재하는 비정상 환경에서 청각 장애인 사용자가 경험하는 피로도를 크게 낮출 수 있음을 시사한다.
한계점으로는 다중 임계값 설정이 환경에 따라 민감하게 변한다는 점과, 실시간 구현 시 SR 계산에 추가적인 연산 비용이 발생한다는 점을 들 수 있다. 향후 연구에서는 머신러닝 기반 임계값 자동 튜닝 및 하드웨어 가속을 통한 실시간 처리 효율성을 개선할 필요가 있다.