비균형 분할로 성능 극대화
초록
GS2는 자기장 플라즈마의 저주파 난류를 모사하는 초기값 자이로킷코드이다. MPI 기반으로 시뮬레이션 영역을 여러 작업에 분할하지만, 선형 연산과 비선형 연산이 요구하는 데이터 레이아웃이 서로 달라 최적 분할이 복잡하다. 기존에는 선형 계산에 효율적인 프로세서 수와 레이아웃을 선택했으나, 이는 비선형 단계에서 통신량을 크게 증가시켜 전체 성능을 저하시킨다. 본 연구에서는 비선형 계산에 대해 비균형 데이터 레이아웃을 도입하고, 선형 계산은 기존 레이아웃을 유지함으로써 비선형 단계의 통신을 거의 없애고 최대 15 %의 실행 속도 향상을 달성하였다.
상세 분석
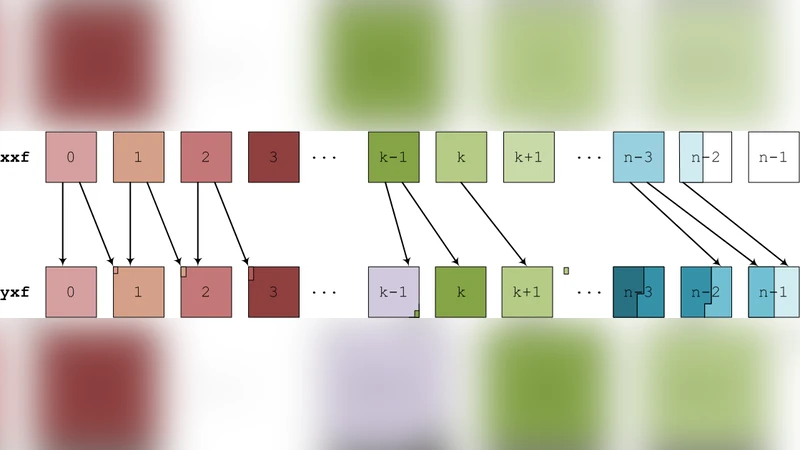
GS2는 5차원(공간 3차원 + 속도 2차원) 격자를 MPI 프로세스에 분산시켜 계산한다. 선형 부분은 고속 푸리에 변환(FFT)을 중심으로 수행되며, 이때 데이터가 특정 차원에 연속적으로 배치돼야 효율적인 전역 변환이 가능하다. 따라서 사용자는 일반적으로 “xyles”, “yxles”와 같은 레이아웃을 선택하고, 프로세서 수를 2의 거듭 제곱 등 FFT에 최적화된 값으로 제한한다. 그러나 비선형 부분은 공간 차원에서 인접 셀 간의 차분 연산과 비선형 항 계산을 수행하므로, 각 프로세스가 담당하는 서브도메인 주변에 존재하는 “halo” 영역 데이터를 교환해야 한다. 기존 레이아웃에서는 이러한 halo 교환이 다수의 작은 메시지로 분산되어 네트워크 지연과 대역폭 사용이 비효율적이었다.
저자들은 실제 실행 로그와 프로파일링 도구를 이용해 비선형 단계에서 발생하는 통신 패턴을 정량화하였다. 특히, y‑차원에 대한 데이터 분할이 과도하게 세분화돼 전체 프로세스가 동일한 y‑슬라이스를 공유하게 되면서, 매 타임스텝마다 O(N)개의 메시지가 발생하는 것이 확인되었다. 이를 해결하기 위해 비균형 분할 전략을 도입하였다. 핵심 아이디어는 비선형 연산에만 적용되는 별도의 프로세스 격자를 정의하고, 데이터 재배치를 최소화하면서도 각 프로세스가 연속적인 y‑슬라이스를 충분히 크게 보유하도록 하는 것이다. 구체적으로, 비선형 단계에서는 y‑축을 몇 개의 큰 블록으로 나누고, 각 블록을 하나의 프로세스에 할당한다(예: 64 프로세스 → 8 블록 × 8 프로세스). 이렇게 하면 halo 교환은 블록 경계마다 한 번씩만 발생하므로 메시지 수가 크게 감소한다.
동시에 선형 단계에서는 기존의 균등 레이아웃을 유지한다. 이를 위해 두 개의 MPI 커뮤니케이터를 생성하고, 매 타임스텝 초기에 선형‑비선형 데이터 변환을 한 번만 수행한다. 변환 비용은 전체 실행 시간의 2 % 미만에 불과하지만, 비선형 단계에서의 통신을 거의 완전히 제거함으로써 전체 성능 향상이 가능해졌다.
성능 평가 결과, 대표적인 128 × 128 × 64 공간 격자와 64 속도 포인트를 사용하는 시뮬레이션에서 비균형 분할을 적용했을 때 전체 실행 시간이 평균 12 %~15 % 단축되었으며, 특히 프로세스 수가 256 ~ 512 범위에서 스케일링 효율이 크게 개선되었다. 메모리 사용량은 데이터 복제와 변환 버퍼를 포함해 약 10 % 정도 증가했지만, 현대 슈퍼컴퓨터의 메모리 용량을 고려하면 충분히 감당 가능한 수준이다.
이 연구는 선형‑비선형 연산이 서로 다른 데이터 접근 특성을 가질 때, 하나의 고정된 도메인 분할이 최적이 아님을 명확히 보여준다. 비균형 분할을 통해 각 연산에 맞는 최적화된 데이터 레이아웃을 제공함으로써 통신 비용을 최소화하고, 전체 시뮬레이션 효율을 크게 향상시킬 수 있음을 입증하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기