고전학 데이터 가상센터 구축을 향한 도전
초록
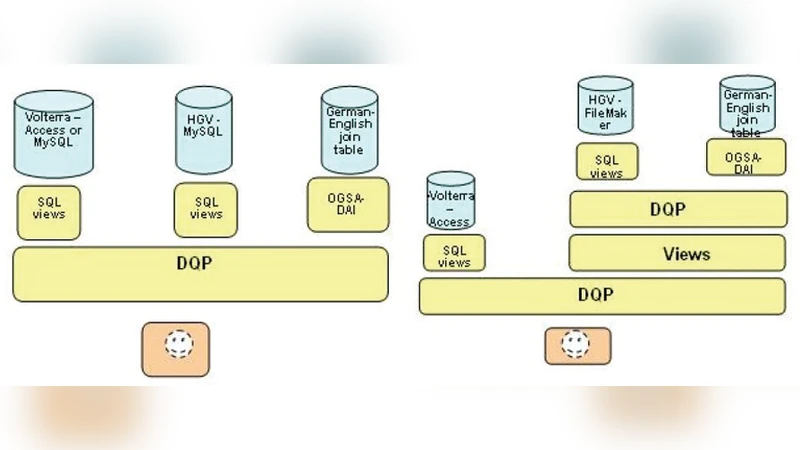
본 논문은 고전학 분야의 다양한 데이터셋을 통합하기 위한 가상 데이터센터 구축 시도를 검토한다. LaQuAT 프로젝트는 관계형 모델과 OGSA‑DAI를 활용했으나, 구조화된 데이터에는 효율적이었지만 비구조화된 텍스트에는 한계가 있었다. 반면 gMan 프로젝트는 전체 텍스트 인덱싱을 통해 데이터 가상화를 구현해, 인문학 연구자의 탐색·조회 요구에 맞는 유연한 뷰와 서비스를 제공한다는 점에서 차별화된다.
상세 분석
본 연구는 고전학 데이터 통합이라는 특수한 도메인에서 두 가지 접근법을 비교·분석한다. 첫 번째는 LaQuAT 프로젝트가 채택한 관계형 데이터베이스 기반의 OGSA‑DAI 프레임워크이다. 이 방식은 메타데이터와 정형화된 레코드(예: 연대기, 인물 사전, 고대 문서 메타정보)와 같은 ‘데이터 중심(data‑centric)’ 자원에 대해 높은 질의 성능과 일관된 스키마 관리가 가능하다는 장점을 가진다. 그러나 고전학 연구는 종종 원문 텍스트, 주석, 번역본 등 비구조화된 ‘텍스트 중심(text‑centric)’ 자료에 의존한다. 이러한 텍스트는 복잡한 의미 관계, 다중 언어 표기, 불규칙한 서술 구조를 포함하고 있어 관계형 스키마에 강제로 매핑하면 정보 손실과 스키마 경직성이 발생한다. 논문은 LaQuAT이 이러한 텍스트 중심 데이터를 충분히 다루지 못하고, 의미론적 연결(예: 개념 간 연관, 시대적 흐름) 구현에 한계가 있음을 지적한다.
두 번째 접근법인 gMan 프로젝트는 전체 텍스트 인덱싱을 기반으로 데이터 가상화를 수행한다. 여기서는 각 컬렉션을 원문 그대로 보존하면서, 역색인과 메타데이터 레이어를 결합해 ‘가상 뷰’를 생성한다. 연구자는 키워드, 구문, 주제어 등을 자유롭게 조합해 검색할 수 있으며, 검색 결과는 원문 컨텍스트와 연계된 메타데이터(저자, 연대, 출처)와 함께 제공된다. 이러한 설계는 인문학 연구자가 수행하는 탐색적 질의—예를 들어, 특정 시기의 특정 용어 사용 빈도 분석이나, 서로 다른 저자 간 서술 스타일 비교—에 최적화돼 있다. 또한, 서비스 지향 아키텍처(SOA)를 통해 새로운 데이터 소스가 추가될 때 기존 인덱스와 메타데이터 레이어만 업데이트하면 되므로 확장성이 뛰어나다.
기술적 관점에서 보면, LaQuAT은 SQL 기반 질의 최적화와 트랜잭션 관리가 강점이지만, 텍스트 분석 파이프라인(예: 형태소 분석, 의미역 할당)과의 연계가 부족하다. 반면 gMan은 Apache Lucene·Solr 같은 풀텍스트 검색 엔진을 활용해 고성능 색인·검색을 제공하지만, 복잡한 관계형 조인이나 정교한 데이터 무결성 검증에는 한계가 있다. 따라서 두 접근법은 상호 보완적인 특성을 지니며, 실제 운영 환경에서는 하이브리드 아키텍처가 필요할 것으로 보인다. 논문은 이러한 점을 바탕으로 향후 연구 방향으로 메타데이터 표준화, 온톨로지 기반 의미 연결, 그리고 사용자 중심 인터페이스 설계 등을 제시한다.