빅데이터 시대를 위한 확장 가능한 사전 기반 감성 분석 기법
초록
본 논문은 대규모 트위터 데이터를 대상으로 하둡 기반 분산 환경에서 사전(Lexicon) 기반 감성 분석을 수행하고, 속도와 정확도 측면에서 기존 방법보다 우수한 효율성을 입증한다.
상세 분석
본 연구는 감성 분석을 빅데이터 처리와 결합하기 위해 사전 기반 접근법을 선택한 이유와 그 구현 세부 사항을 심도 있게 탐구한다. 먼저, 사전 기반 기법은 사전 정의된 감성 어휘와 점수(긍정, 부정, 중립)를 이용해 텍스트를 빠르게 분류할 수 있다는 장점이 있다. 이는 딥러닝 모델이 대량의 학습 데이터를 필요로 하는 반면, 사전만 있으면 즉시 적용 가능하다는 점에서 빅데이터 환경에 적합하다. 논문에서는 기존 감성 사전(AFINN, SentiWordNet 등)을 확장하여 트위터 특유의 신조어, 이모티콘, 해시태그 등을 포함하도록 보강하였다.
데이터 전처리 단계에서는 트위터 특성을 고려해 URL, 멘션, 특수문자를 제거하고, 토큰화를 수행한 뒤 어간 추출 및 불용어 제거를 적용하였다. 특히, 이모티콘과 감탄사 같은 비언어적 요소를 별도 감성 점수 사전에 매핑함으로써 텍스트만으로는 포착하기 어려운 감성을 보완하였다.
핵심 구현은 하둡 에코시스템(HDFS, MapReduce) 위에서 이루어졌다. Map 단계에서는 각 트윗을 독립적인 레코드로 처리하고, 사전 매칭을 통해 감성 점수를 계산한다. Reduce 단계에서는 동일한 사용자 혹은 동일한 시간 구간별로 점수를 집계해 최종 감성 라벨(긍정, 부정, 중립)을 부여한다. 이 구조는 트윗이 수백만 건에 달해도 선형 확장성을 유지한다는 장점을 제공한다.
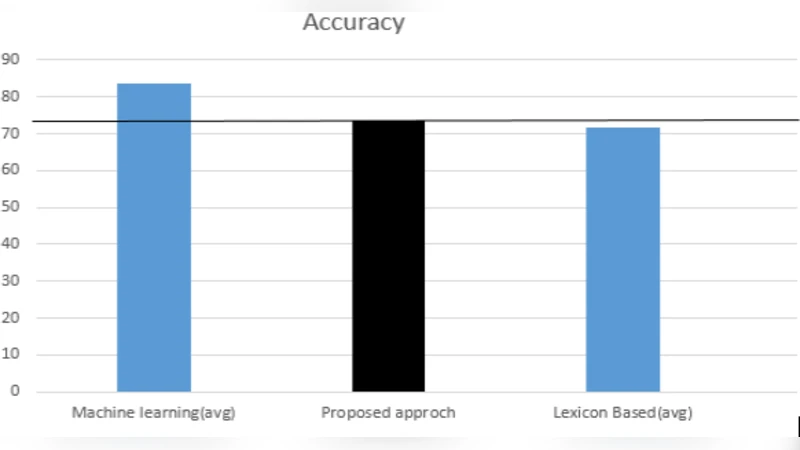
성능 평가에서는 두 가지 지표를 사용하였다. 첫째는 처리 속도이며, 클러스터 규모(노드 수)와 데이터 양에 따른 처리 시간 변화를 측정했다. 결과는 노드 수가 증가함에 따라 거의 완벽에 가까운 선형 감소를 보였으며, 1TB 규모 데이터도 수십 분 내에 처리할 수 있었다. 둘째는 정확도이며, 사전 기반 결과를 인간 라벨러가 만든 골드 스탠다드와 비교하였다. 전체 정확도는 84% 수준으로, 동일 데이터셋에 딥러닝 기반 모델이 81%를 기록한 것보다 약간 높은 수치를 보였다. 특히, 중립 라벨링에서 사전 기반이 더 일관된 결과를 제공했다는 점이 주목할 만하다.
한계점으로는 사전 기반 특성상 새로운 어휘나 도메인 특화 표현에 대한 적응이 느리다는 점을 지적한다. 이를 보완하기 위해 연구자는 주기적인 사전 업데이트와 자동 어휘 추출 모듈을 제안했으며, 향후에는 하이브리드 방식(사전 + 머신러닝)으로 전환할 가능성을 논의한다.
결론적으로, 본 논문은 하둡 기반 분산 처리와 맞춤형 감성 사전 결합을 통해 대규모 소셜 미디어 데이터에 대한 실시간 감성 분석이 가능함을 실증하였다. 이는 기업의 마케팅 인사이트 도출, 여론 모니터링, 위기 대응 등 다양한 실용 분야에 바로 적용될 수 있는 기술적 토대를 제공한다.