대규모 데이터 병렬 추정의 새로운 패러다임 Median Selection Subset Aggregation
본 논문은 대용량 데이터에서 통신 비용을 최소화하면서 변수 선택과 계수 추정을 동시에 수행할 수 있는 MESSAGE 알고리즘을 제안한다. 각 데이터 서브셋에 대해 Lasso 혹은 GIC 기반 변수 선택을 수행하고, 선택된 변수들의 포함 여부를 ‘중위수’ 방식으로 집계한다. 이후 선택된 변수에 대해 서브셋별 OLS 추정을 수행하고, 최종 계수는 평균한다. 이 과정은 통신량이 거의 없으며, 이론적으로 모델 선택 일관성과 추정 효율성을 보장한다. 실…
저자: Xiangyu Wang, Peichao Peng, David Dunson
**1. 서론**
데이터 양과 속도가 급격히 증가함에 따라, 전통적인 단일 머신 기반 통계 분석은 메모리·연산 한계에 부딪힌다. 병렬·분산 처리 방식은 데이터를 여러 서브셋으로 나누어 각 머신에서 동시에 연산함으로써 시간 복잡도를 크게 낮출 수 있다. 그러나 대부분의 기존 분산 알고리즘은 매 반복마다 중앙 서버와 통신을 필요로 하며, 통신 비용이 전체 효율을 좌우한다. 특히 회귀·분류와 같이 변수 선택과 파라미터 추정이 동시에 요구되는 문제에서는, 단순히 파라미터 평균을 취하는 방식이 변수 선택 정확도를 크게 떨어뜨린다. 이러한 배경에서 저자들은 “통신을 최소화하면서도 변수 선택과 추정 모두에서 이론적·실제적 우수성을 보장하는” 새로운 방법을 제시하고자 한다.
**2. 관련 연구**
분산 베이지안 방법, 샤딩 기반 최적화, M‑estimator 기반 평균·중위수 집계 등이 소개된다. 특히 Mann et al.와 Zhang et al.는 서브셋 추정값을 평균하거나 기하 평균(geometric median)으로 결합해 통계적 효율성을 확보했지만, 변수 선택 단계에 대한 특별한 설계가 없었다. Bolasso는 부트스트랩 Lasso를 이용해 변수 선택을 강화했지만, 전체 데이터를 그대로 사용하므로 통신·연산 이점이 제한적이다.
**3. MESSAGE 알고리즘 설계**
알고리즘은 크게 네 단계로 구성된다.
① **데이터 분할**: 전체 (Y, X)를 무작위로 m 개의 서브셋으로 나눈다.
② **서브셋별 변수 선택**: 각 서브셋에서 Lasso 혹은 GIC(ℓ₀ 기반)로 변수 포함 지표 γ⁽ⁱ⁾ (0‑1 벡터)를 얻는다.
③ **중위수 모델 집계**: 각 변수 j에 대해 γⱼ = median{γ⁽ⁱ⁾ⱼ} 을 계산한다. 즉, 다수 서브셋에서 선택된 변수만을 최종 모델에 포함한다.
④ **계수 추정 및 평균**: 선택된 변수 집합에 대해 각 서브셋에서 OLS(또는 가중 최소제곱) 추정을 수행하고, 최종 계수 \(\bar β\) 는 모든 서브셋 추정값의 산술 평균으로 결합한다.
통신은 단계 ②와 ③ 사이에 변수 포함 지표(길이 p)만을 전송하고, 단계 ④에서 각 서브셋이 추정값을 전송해 평균을 구하는 두 번에 국한된다. 따라서 통신량은 O(p + p·m) 정도이며, 실제로는 매우 작다.
**4. 이론적 분석**
알고리즘의 통계적 성질을 보장하기 위해 네 가지 가정(A.1–A.4)을 설정한다. A.1은 디자인 매트릭스의 유계 공분산, A.2는 오류의 유한 고계 모멘트와 신호 강도, A.3은 Lasso의 강 irrepresentable condition, A.4는 GIC의 sparse Riesz condition을 의미한다.
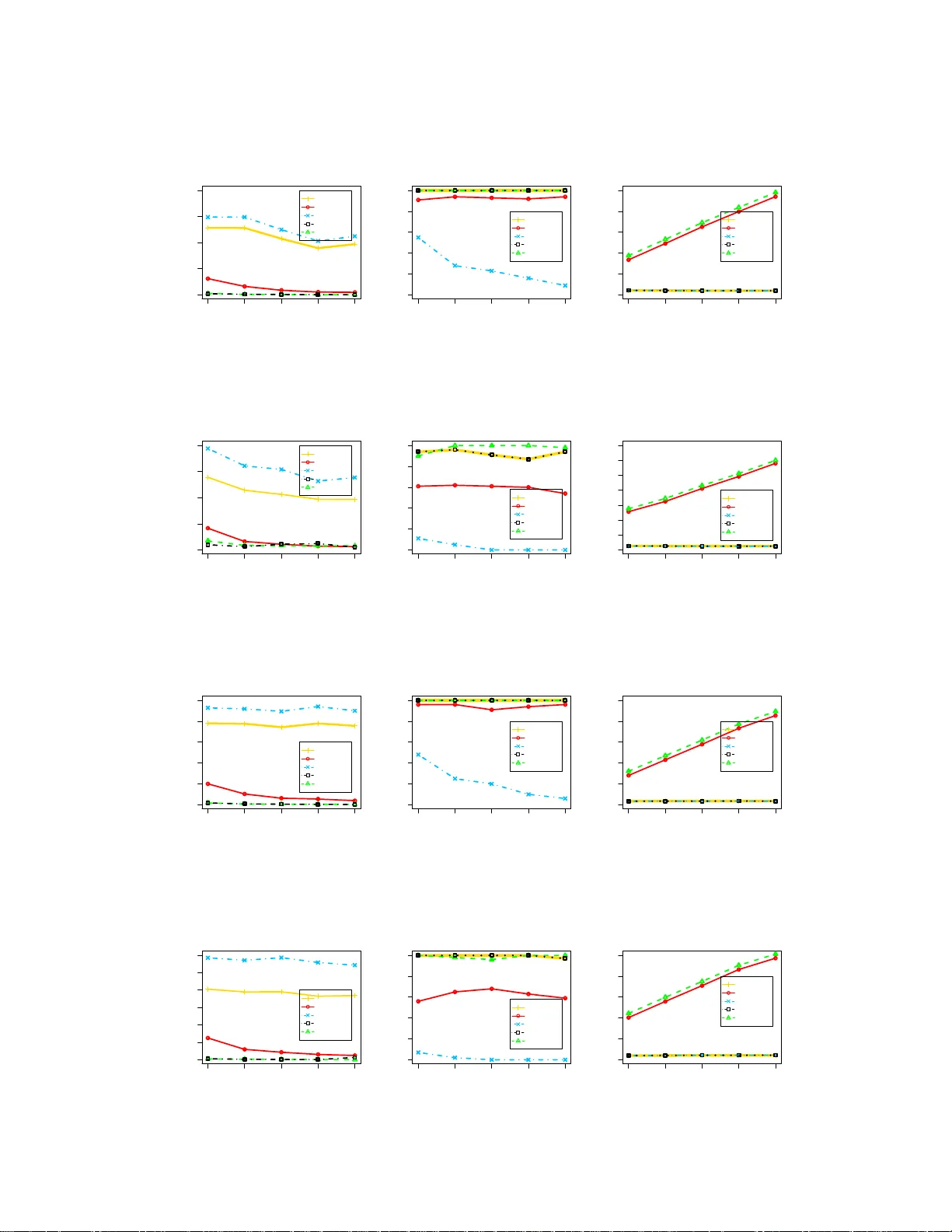
- **모델 선택 일관성**: 정리 1(GIC)와 정리 2(Lasso)는 각각 중위수 모델 M_γ 가 진짜 모델 M_S 와 일치할 확률이 \(1 - \exp(-c n^{1-\alpha/(k\tau-\eta)})\) 형태로 지수적으로 수렴함을 보인다. 이는 기존 다항식 수렴률보다 훨씬 빠른 속도이며, 특히 중량 꼬리 오류(heavy‑tailed) 상황에서도 강건함을 제공한다.
- **계수 추정 효율성**: 중위수 모델을 사용한 후 평균 결합한 계수 \(\bar β\) 의 평균 제곱 오차(MSE)는
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기