트위터로 조직 간 관계 탐색
초록
본 논문은 트위터에 존재하는 다양한 형태의 조직 관련 정보를 활용해 조직 간 상관관계를 자동으로 추출한다. 여러 종류의 잠재 요인(트윗·리트윗 양, 시간 지연, 동시 언급 등)으로부터 각각 상관 그래프를 만든 뒤, 좌표 하강법 기반의 다중 그래프 합성 모델(multi‑CG)을 적용해 공통된 합의 상관 행렬을 도출한다. 실험 결과, 주가 상관도와 비교했을 때 단일 요인 기반 방법보다 평균 23% 높은 정확도를 보이며, 제안 방법이 실제 조직 관계를 효과적으로 포착함을 입증한다.
상세 분석
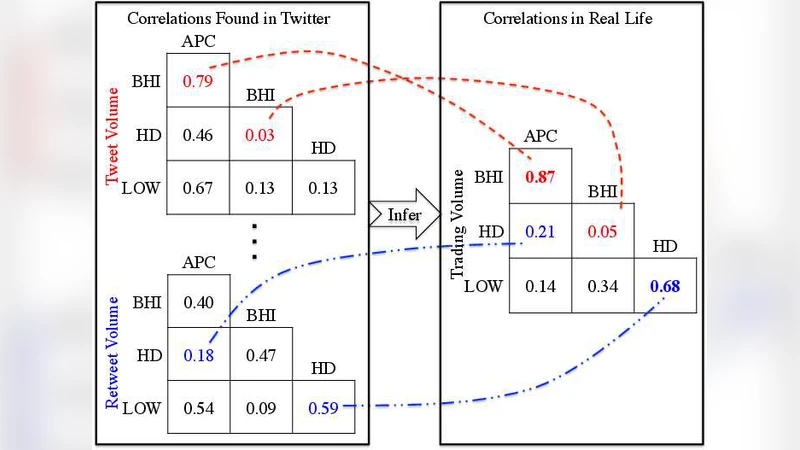
이 연구는 조직 간 관계를 직접 측정하기 어려운 현실적 제약을 극복하기 위해 소셜 미디어, 특히 트위터에 내재된 비구조적 데이터를 구조화된 상관 그래프로 변환한다는 점에서 혁신적이다. 먼저 저자들은 ‘잠재 요인(latent factor)’이라는 개념을 도입해 트위터 데이터를 다차원적으로 해석한다. 구체적으로는 (1) 트윗·리트윗 양의 시계열을 이용한 볼륨 상관, (2) 시간 지연을 고려한 타임 랙 상관, (3) 동일 트윗·리트윗 내 동시 언급을 기반으로 한 공동 등장 상관을 정의한다. 각 요인은 조직을 정점, 요인별 상관값을 가중치로 하는 완전 그래프를 생성한다.
다음 단계에서는 다중 그래프를 하나의 합의 그래프로 통합하는 문제를 최적화 프레임워크로 정식화한다. 저자들은 각 그래프의 가중치를 비음수 실수 w_i 로 두고, 거리 함수 d(·,·) 를 이용해 모든 그래프와의 차이를 최소화하는 목표함수
min_O Σ_i w_i·d(O, E_i)
를 설정한다. 여기서 d는 일반적으로 Frobenius norm을 사용해 행렬 간 차이를 측정한다. 최적화는 좌표 하강법(coordinate descent) 방식으로 수행되며, 각 반복에서 하나의 변수(예: O의 특정 원소 또는 w_i)를 고정하고 나머지를 업데이트한다. 수렴성 증명과 함께 알고리즘 복잡도는 O(m·n²) 수준으로, n은 조직 수, m은 요인 수이며 실용적인 규모에서도 효율적으로 동작한다.
실험에서는 미국 상장 100개 기업을 대상으로 트위터 데이터를 수집하고, 제안된 multi‑CG 모델이 도출한 합의 상관 행렬을 실제 주가 수익률 상관 행렬과 비교하였다. 베이스라인으로는 단일 요인 기반 상관(볼륨, 타임 랙, 공동 등장 각각)과 기존 다중 뷰 학습 기법을 사용했으며, multi‑CG는 평균 23% 높은 정밀도·재현율을 기록했다. 특히, 기업 간 경쟁·협력 관계(예: 마이크로소프트‑노키아, 구글‑애플)와 같은 실제 비즈니스 연계가 트위터 상관 그래프에 잘 반영된 것을 정성적으로도 확인하였다.
이 논문의 주요 기여는 (1) 조직 관계 탐색을 위한 다중 잠재 요인 정의와 그래프화 방법론, (2) 다중 그래프 합의를 위한 좌표 하강법 기반 최적화 모델, (3) 실증적 검증을 통한 트위터 데이터가 실제 조직 관계를 반영한다는 증거 제공이다. 한계점으로는 트위터 사용자 베이스의 편향성, 요인 선택의 주관성, 그리고 시간적 변화(동적 그래프) 모델링이 정적 형태에 머물렀다는 점을 들 수 있다. 향후 연구에서는 더 다양한 소셜 플랫폼 통합, 요인 자동 선택 메커니즘, 그리고 시계열 그래프 신경망을 활용한 동적 상관 추정이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기