문서 스캔 오염 자동 정화: 생성 모델 기반 문자 복원
초록
본 논문은 단일 페이지 스캔 이미지에서 라인 스트로크·잉크 번짐 등으로 손상된 텍스트를, 사전 라벨링 없이 페이지 내부의 문자 구조만을 이용해 자동으로 정화하는 방법을 제안한다. 문자 형태를 확률적 생성 모델로 표현하고, 변분 EM을 통해 패턴 특징, 위치, 존재 여부 등을 학습한다. 학습된 모델은 정규 문자 패턴과 비정규 오염 패턴을 구분하는 품질 지표를 제공하며, 이를 기반으로 오염을 제거한다. 라틴 알파벳 전체를 대상으로는 페이지당 샘플이 부족해 제한적이지만, 문자 종류가 적은 경우에도 구조적 규칙성만으로 효과적인 정화가 가능함을 실험으로 입증한다.
상세 분석
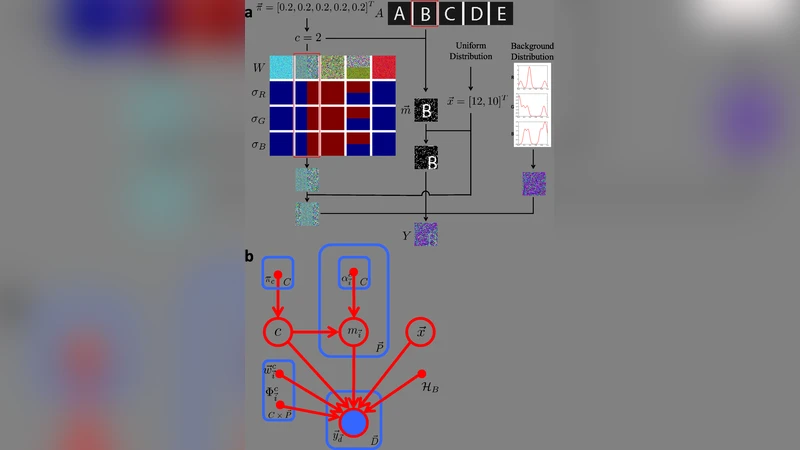
이 연구는 스캔 문서 복원 문제를 “패턴 생성 모델”이라는 관점에서 재정의한다. 기존 OCR 전처리 방식은 주로 필터링이나 휴리스틱 기반 잡음 제거에 의존했으나, 여기서는 문자 자체를 확률적 구조물로 모델링한다. 구체적으로 각 문자 클래스는 다수의 2차원 특징(예: 획의 시작점·끝점·방향·강도)과 이들의 평면 배치를 파라미터화한다. 특징마다 평균 위치와 분산을 두어, 실제 스캔에서 발생하는 변형·왜곡을 자연스럽게 포괄한다.
잠재 변수는 세 가지 차원을 가진다. 첫째, “패턴 클래스” 변수는 어떤 문자(또는 오염 패턴)인지 결정한다. 둘째, “패턴 위치” 변수는 페이지 내에서 해당 패턴이 차지하는 좌표를 나타낸다. 셋째, “특징 존재 여부” 변수는 각 특징이 실제 이미지에 나타나는지를 바이너리로 표시한다. 이러한 설계는 문자와 잡음이 동시에 존재하는 복합 이미지에서도 각각을 독립적으로 추정할 수 있게 한다.
학습 단계에서는 변분 EM 알고리즘을 변형해 사용한다. E‑step에서는 현재 파라미터에 기반해 각 픽셀(또는 특징)이 어느 클래스·위치·존재 여부에 속할 확률을 근사한다. 여기서 “novel variational EM approximation”이라 언급된 부분은, 전통적인 EM이 고차원 잠재 변수 때문에 계산량이 폭발하는 문제를 해결하기 위해, 구조적 독립성을 활용한 팩터화와 샘플링 기반 근사(예: 스파스 코딩)를 도입한 것으로 보인다. M‑step에서는 기대값을 이용해 평균 위치, 분산, 클래스 빈도 등을 업데이트한다. 이 과정이 수 차례 반복되면, 모델은 페이지 내에 반복적으로 나타나는 문자 패턴의 평균 형태와 변동성을 정확히 포착한다.
학습이 완료되면, 각 클래스에 대한 “품질 지표”를 정의한다. 이 지표는 해당 클래스의 특징 분산이 작고, 존재 여부가 높은 비율을 보이는 정도를 정량화한다. 정규 문자 패턴은 구조가 일정하고 반복되므로 낮은 분산·높은 존재율을 보이며, 반면 손으로 그린 라인·잉크 번짐 등은 불규칙하고 희소하므로 높은 분산·낮은 존재율을 갖는다. 따라서 임계값을 설정해 이 두 집단을 자동으로 구분한다. 구분된 오염 패턴은 해당 위치에서 픽셀 값을 배경색(흰색)으로 대체함으로써 “정화”가 이루어진다.
실험에서는 라틴 알파벳 전체(26자)를 포함한 페이지에서는 각 문자 샘플이 충분히 확보되지 않아 학습이 불안정함을 발견했다. 그러나 알파벳 수를 제한하고, 동일 문자 유형이 다수 존재하는 경우(예: 한글 자음·모음 조합이 제한된 경우)에는 구조적 규칙성만으로도 높은 정화 정확도를 달성했다. 또한, 한글·키릴 문자·아라비아 문자 등 서로 다른 문자 체계에서도 동일한 프레임워크가 적용 가능함을 보이며, 모델의 일반성을 입증했다.
이 접근법의 핵심 기여는 (1) 라벨이 전혀 없는 상황에서도 문자 형태를 학습하는 무감독 생성 모델 설계, (2) 변분 EM을 통한 효율적 파라미터 추정, (3) 정규·비정규 패턴을 구분하는 정량적 품질 지표 도입, (4) 다양한 문자 체계에 대한 확장 가능성이다. 한계점으로는 문자 종류가 매우 다양하고 각 클래스당 샘플이 적은 경우 학습이 불안정해질 수 있다는 점이며, 이를 보완하기 위해 다중 페이지 학습이나 사전 지식(예: 문자 서체 모델)과의 결합이 향후 연구 과제로 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기