CUDA와 MapReduce 그리고 Pthreads 비교 분석
초록
본 논문은 고성능 컴퓨팅 환경에서 널리 사용되는 세 가지 병렬 프로그래밍 모델인 CUDA, MapReduce, Pthreads를 비교·분석한다. 각 모델의 설계 철학, 실행 구조, 메모리 관리 방식, 확장성 및 사용 사례를 문헌 조사와 사례 연구를 통해 정리하고, 빅데이터 처리와 과학 계산에 적합한 모델 선택을 위한 가이드라인을 제시한다.
상세 분석
CUDA는 NVIDIA GPU의 대규모 SIMD(단일 명령 다중 데이터) 아키텍처를 활용해 수천 개의 스레드를 동시에 실행한다. 커널 함수와 메모리 계층(전역, 공유, 텍스처, 상수 메모리)을 명시적으로 관리함으로써 메모리 대역폭과 연산 집약도를 최적화한다. 특히, 스레드 블록과 그리드 구조는 하드웨어 스케줄러와 연동되어 워프 단위의 동기화와 분기 최소화를 가능하게 한다. 그러나 CUDA는 GPU 전용 코드와 호스트‑디바이스 간 데이터 전송 비용이 존재하며, 디버깅 및 포팅이 제한적이다.
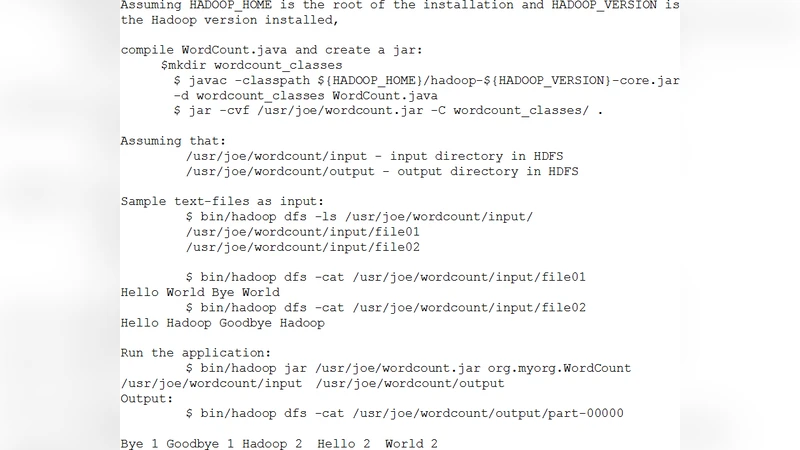
MapReduce는 구글이 제안한 분산 데이터 처리 모델로, 입력 데이터를 키-값 쌍으로 매핑하고, 셔플 단계에서 같은 키를 가진 데이터를 그룹화한 뒤, 리듀스 함수로 집계한다. 이 모델은 데이터 로컬리티와 장애 복구를 자동화하며, 클러스터 규모에 따라 선형적인 확장성을 제공한다. 구현체인 Hadoop은 HDFS와 YARN을 통해 자원 관리와 작업 스케줄링을 담당한다. 하지만 MapReduce는 반복적인 알고리즘(예: 그래프 처리)이나 실시간 스트리밍에 비효율적이며, 작업 단계가 고정돼 있어 세밀한 스레드 제어가 어렵다.
Pthreads는 POSIX 표준 스레드 라이브러리로, CPU 코어 수준에서 직접적인 멀티스레딩을 구현한다. 스레드 생성·소멸, 뮤텍스, 조건 변수, 바리어 등을 통해 동기화와 자원 공유를 정교하게 제어한다. 이 모델은 저수준 접근성을 제공해 성능 튜닝이 자유롭지만, 레이스 컨디션, 데드락 등 복잡한 동시성 버그가 발생하기 쉬우며, 개발 비용이 높다. 또한, 메모리 일관성 모델과 캐시 동기화에 대한 깊은 이해가 필요하다.
세 모델을 비교하면, CUDA는 연산 집약적인 GPU 가속에 최적이며, MapReduce는 대규모 분산 파일 처리와 배치 작업에 강점이 있다. Pthreads는 CPU 기반의 세밀한 병렬 제어와 실시간 응용에 적합하지만, 프로그래머에게 높은 숙련도를 요구한다. 논문은 이러한 특성을 기반으로 작업 유형(예: 행렬 연산, 텍스트 검색, 시뮬레이션)과 시스템 환경(단일 노드 vs 클러스터, 메모리 용량, 네트워크 대역폭)에 따라 모델 선택 전략을 제시한다. 또한, 하이브리드 접근법—예를 들어, CPU에서 Pthreads로 전처리를 수행하고, GPU에서 CUDA 커널로 핵심 연산을 가속화하거나, MapReduce 파이프라인 내에서 CUDA 작업을 삽입하는 방안—이 실제 프로젝트에서 성능 향상을 가져올 수 있음을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기