디바이스 기반 강화학습을 활용한 최적 수요반응 관리
초록
본 논문은 주거·소형 상업 건물의 수요반응(DR) 문제를 디바이스 클러스터별로 분할 가능한 강화학습(RL) 형태로 재구성한다. 사용자 불만 함수를 사전에 정의하지 않고, EMS가 사용자 피드백을 통해 학습하도록 설계했으며, EMS 자체가 작업을 시작할 수 있게 함으로써 자율성을 높였다. 또한 알고리즘의 복잡도가 디바이스 수에 대해 선형으로 증가하도록 하여 대규모 적용 가능성을 확보한다. Q‑learning을 이용한 시뮬레이션 결과를 제시한다.
상세 분석
이 논문은 기존의 수요반응(DR) 연구가 사용자 불만(disutility) 함수를 미리 정의하고, 사용자가 직접 작업을 요청하는 전제에 의존하는 한계를 지적한다. 저자는 두 가지 핵심 아이디어를 제시한다. 첫째, 사용자 불만을 명시적으로 모델링하지 않고, 사용자가 작업 완료 후 제공하는 평가(evaluation)를 통해 EMS가 불만을 추정하도록 설계하였다. 이는 개별 가구나 소규모 사업장의 불만 함수가 고유하고 측정하기 어려운 현실을 반영한다. 둘째, EMS가 자체적으로 작업을 시작(EMS‑initiated job)할 수 있게 함으로써, 사용자가 직접 요청하지 않는 장치(예: HVAC, 풀 히터 등)의 에너지 사용을 최적화한다. 이러한 접근은 기존 연구가 “사용자 요청 → EMS 스케줄링” 일방향 흐름에 머물렀던 점을 탈피한다.
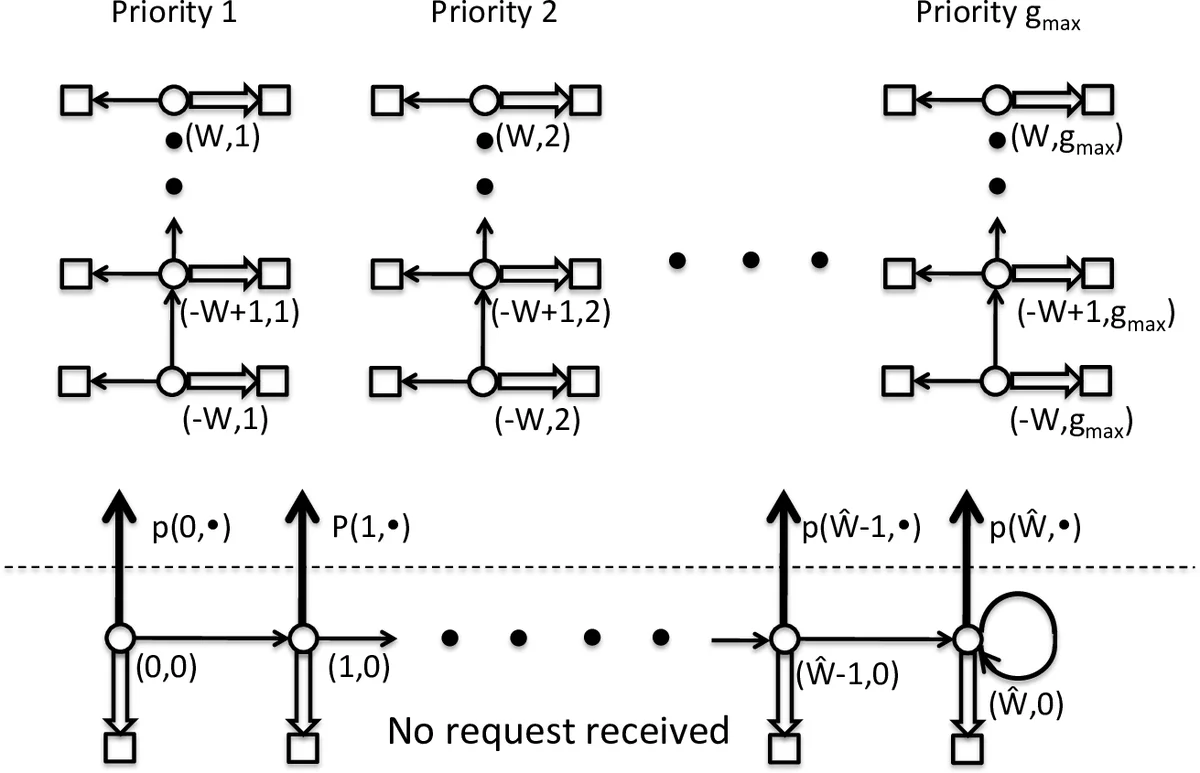
기술적 핵심은 불만 함수가 디바이스별로 가법(additive)이라고 가정하고, 전체 최적화 문제를 디바이스 클러스터별 MDP로 분해한다는 점이다(Assumption 1). 이 가정은 ‘의사결정 피로도’를 고려해 개별 디바이스의 불만이 서로 독립적이라고 보는 실용적 근거를 제공한다. 결과적으로 각 클러스터에 대해 독립적인 RL 에이전트를 학습시킬 수 있어, 상태·행동 공간이 디바이스 수에 비례하는 선형 복잡도로 축소된다.
RL 모델링에서는 즉시 비용을 전력 가격과 디바이스별 에너지 소비량 Cₙ, 그리고 가중치 γ를 곱한 불만 함수의 합으로 정의한다. 상태는 현재 시각, 가격 예측, 각 디바이스의 예약·취소 이력 등으로 구성되며, 행동은 “작업 실행”, “대기”, “취소” 등을 포함한다. 논문은 가장 기본적인 Q‑learning 알고리즘을 적용했으며, 시뮬레이션을 통해 수렴 과정을 보여준다.
강점으로는 (1) 사용자 불만을 사전 모델링하지 않아 실무 적용 장벽을 낮추고, (2) EMS‑initiated 작업을 허용해 실제 건물 운영에 더 적합한 제어가 가능하며, (3) 선형 복잡도로 대규모 디바이스 환경에 확장 가능하다는 점을 들 수 있다. 반면 약점은 가법성 가정이 현실에서 완전히 성립하기 어렵고, 디바이스 간 상호작용(예: 전력 피크 제한)이나 전력망 제약을 충분히 반영하지 못한다는 점이다. 또한 Q‑learning은 상태·행동 공간이 커질 경우 수렴 속도가 급격히 저하되며, 탐색·활용 균형을 위한 파라미터 튜닝이 필요하다. 논문은 시뮬레이션만을 제시하고 실제 현장 데이터 검증이 부족하므로, 실증 연구가 뒤따라야 한다. 마지막으로, 불만 함수 추정을 위한 사용자 평가 메커니즘이 구체적으로 어떻게 설계·수집될지에 대한 실무적 논의가 부족하다.
전반적으로 이 연구는 디바이스 기반 RL을 통한 DR 문제의 구조적 단순화와 실용적 구현 방안을 제시했으며, 향후 딥 RL, 다중 에이전트 협업, 실제 건물 파일럿 테스트 등으로 확장될 여지를 충분히 남긴다.
댓글 및 학술 토론
Loading comments...
의견 남기기