시간 정보를 활용한 전파 네트워크 재구성
본 논문은 전파 과정에서 얻은 노드 간 수신 뉴스와 그 시간 정보를 이용해 네트워크 구조를 복원하는 방법을 제안한다. 기존 유사도 기반 재구성 방법은 감염률에 크게 좌우되며, 특정 감염률 구간에서는 정확도가 급격히 떨어진다. 저자들은 이러한 문제를 해결하기 위해 시간 차이를 가중치로 포함한 ‘시간 유사도’ 지표들을 설계하고, 인공 및 실제 네트워크 실험을 통해 기존 방법 대비 재구성 정확도와 정밀도가 크게 향상됨을 입증한다.
저자: Hao Liao, An Zeng
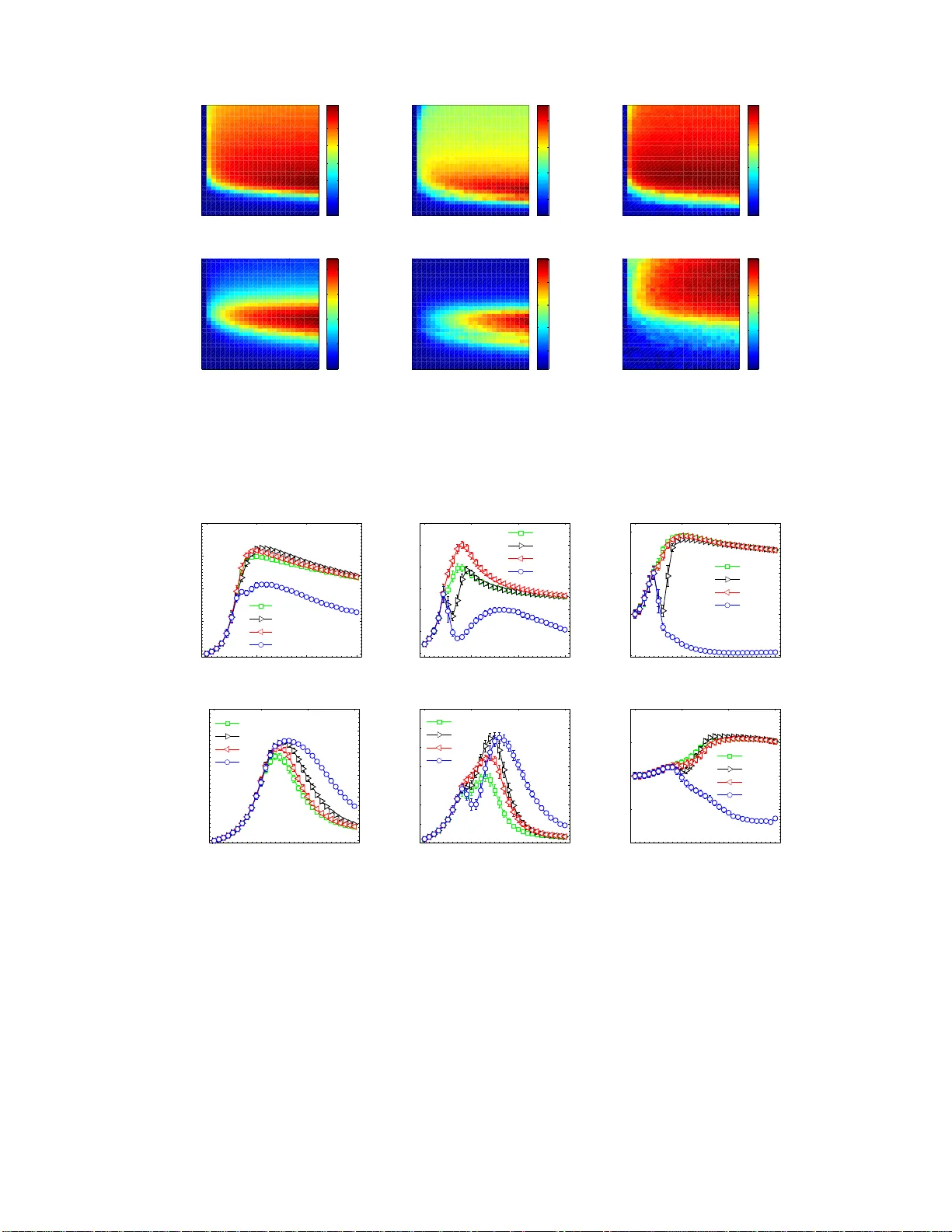
본 논문은 “전파 네트워크 재구성”이라는 새로운 문제에 초점을 맞추어, 전파 과정에서 관찰된 데이터만을 이용해 원본 네트워크 구조를 복원하는 방법을 탐구한다. 연구 배경으로는 노드 간 유사도가 복잡계 네트워크 성장과 연결 형성에 핵심적인 역할을 한다는 점을 들며, 기존에는 링크 예측, 추천 시스템, 스파리어스 링크 식별 등 다양한 분야에 활용되어 왔다. 그러나 전파 네트워크 복원은 기존 유사도 기반 방법과는 다른 목표를 가진다. 여기서는 실제 존재하는 링크를 정확히 찾아내는 것뿐 아니라, 거짓 양성 링크를 최소화하고, 복원된 네트워크의 전반적인 구조(특히 노드 차수 분포)를 정확히 반영해야 한다.
연구는 먼저 SIR 모델을 활용해 뉴스(또는 바이러스) 전파를 시뮬레이션한다. 각 노드 i는 확률 f 로 새로운 뉴스를 생성하고, 생성된 뉴스 α는 감염률 β 로 인접 노드에 전파된다. 전파 과정에서 각 노드가 어떤 뉴스 α를 받았는지(R 행렬)와 언제 받았는지(T 행렬)를 기록한다. 목표는 이 두 행렬만을 가지고 원본 인접 행렬 A 를 추정하는 것이다.
전통적인 유사도 지표 네 가지를 선택했다. (i) Common Neighbor(CN): 단순히 공통 뉴스 수를 합산. (ii) Jaccard(Jac): 공통 뉴스 수를 두 노드가 받은 전체 뉴스 수로 정규화. (iii) Resource Allocation(RA): 한 노드가 다른 노드에 전달한 자원의 양을 기반으로 함. (iv) Leicht‑Holme‑Newman(LHN): 공통 뉴스 수를 기대값으로 나눈 형태. 이들 지표는 모두 R 행렬만을 이용해 계산된다.
하지만 실험 결과, 감염률 β가 네트워크에 따라 최적값을 가질 때는 AUC가 높게 나오지만, β가 약간만 변해도 Precision과 차수 상관관계가 급격히 떨어지는 ‘특수 β 구간’이 존재한다. 특히 Jaccard과 LHN은 정규화 항이 큰 차수 노드의 유사도를 과도하게 억제해, 높은 β에서 대부분의 링크가 저차수 노드에만 집중되면서 재구성 정확도가 거의 0에 수렴한다.
이를 해결하기 위해 저자들은 시간 정보를 활용한 네 가지 ‘시간 유사도’ 지표를 제안한다. 기본 아이디어는 동일 뉴스에 대해 거의 동시에 수신한 두 노드가 실제로 연결될 가능성이 높다는 가정이다. 구체적으로, (Δt)⁻¹ 를 가중치로 도입해 기존 유사도에 곱하거나 나누는 형태로 정의하였다. Δt가 0이면 가중치를 0으로 설정해 자기 전파를 배제한다. 제안된 지표는 TCN, TJac, TRA, TLHN이다.
실험은 두 종류의 인공 네트워크와 실제 소셜 네트워크 데이터를 사용했다. 인공 네트워크는 Small‑World(SW)와 Barabási‑Albert(BA) 모델이며, 각각 N=500, 평균 차수 10 정도로 설정했다. 파라미터 β와 f 를 다양하게 바꾸어 AUC, Precision, 차수 상관관계를 측정했다. 주요 결과는 다음과 같다. 1) CN은 β가 최적값 근처에서 AUC가 최고이지만, Precision과 차수 상관관계는 급격히 감소한다. 2) Jaccard과 LHN은 AUC는 여전히 피크를 보이지만, Precision과 차수 상관관계는 특수 β 구간에서 거의 0이 된다. 3) RA는 전반적으로 가장 안정적인 성능을 보이며, 특히 β가 중간값일 때도 높은 AUC와 Precision을 유지한다. 4) 시간 가중치를 추가한 TCN, TJac, TRA, TLHN은 모든 β 구간에서 기존 지표보다 높은 Precision과 차수 상관관계를 기록한다. 특히 특수 β 구간에서 기존 방법이 0에 가까운 정확도를 보였던 반면, 시간 유사도는 0.2~0.4 수준까지 회복한다.
또한, 뉴스 수신 횟수 d_ij(공통 뉴스 수)의 분포가 β에 따라 얼마나 이질적인지를 Gini 계수로 측정했다. 결과는 β가 특수 구간에 있을 때 Gini가 최대가 되어 d_ij가 매우 불균형하게 분포함을 보여준다. 이는 Jaccard과 LHN의 정규화 항이 큰 차수 노드에 불리하게 작용하는 원인이다. 시간 가중치는 이러한 불균형을 보정해, 실제 연결 가능성이 높은 노드 쌍을 더 정확히 식별한다.
결론적으로, 전파 과정에서 얻을 수 있는 시간 스탬프는 네트워크 복원에 중요한 부가 정보이며, 제안된 시간 유사도 지표는 기존 유사도 기반 방법의 한계를 효과적으로 극복한다. 이는 대규모 온라인 소셜 네트워크, 테러 조직 탐지, 바이오 네트워크 등 실시간 전파 데이터가 존재하는 다양한 분야에서 효율적이고 정확한 구조 추정에 활용될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기