이기종 멀티코어로 가속하는 장바구니 분석 알고리즘
초록
본 논문은 이기종 멀티코어 프로세서를 활용해 Apriori 기반 장바구니 분석 알고리즘의 효율을 높이는 방안을 제시한다. Hadoop Map/Reduce 환경에 MB Scheduler를 도입해 정적·동적 코어 스위칭을 제어하고, 연산량과 전력 소비를 최적화한다.
상세 분석
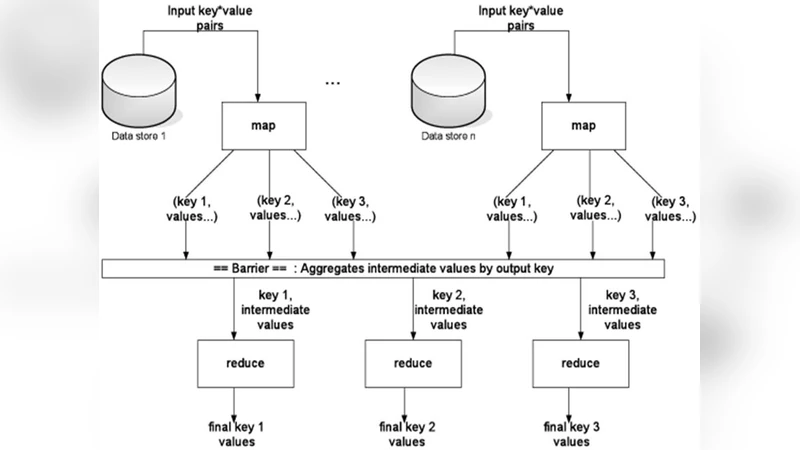
본 연구는 데이터 마이닝에서 가장 널리 사용되는 연관 규칙 탐색 기법인 Apriori 알고리즘을 이기종 멀티코어 환경에 매핑함으로써 처리 속도와 전력 효율을 동시에 개선하고자 한다. 전통적인 Hadoop Map/Reduce는 동일한 성능을 가진 코어들 위에서 작업을 분산시키는 것이 전제였으나, 최근 모바일 및 서버 시장에서 CPU, GPU, DSP 등 서로 다른 연산 특성을 가진 코어가 하나의 칩에 집적되는 이기종 설계가 보편화되었다. 이러한 환경에서는 작업의 특성에 따라 가장 적합한 코어에 할당하는 스케줄링 전략이 필수적이다.
논문은 먼저 Apriori 알고리즘의 주요 연산을 두 종류로 구분한다. (1) 빈도 집합 생성 단계는 대량의 키‑값 페어를 생성·정렬하는 I/O‑중심 연산이며, 메모리 대역폭이 높은 코어(예: 고성능 CPU 코어)에서 효율적이다. (2) 후보 집합 검증 단계는 복잡한 조합 연산과 해시 테이블 탐색을 포함하므로, SIMD 명령어와 대규모 연산 유닛을 갖춘 코어(예: GPU 혹은 특수 목적 코어)에서 가속 효과가 크다.
이를 기반으로 제안된 MB Scheduler는 작업을 정적 스케줄링과 동적 스케줄링 두 모드로 운영한다. 정적 모드에서는 사전에 정의된 매핑 테이블에 따라 Map 단계와 Reduce 단계 각각을 특정 코어 풀에 고정 배정한다. 이 방식은 작업 부하가 예측 가능하고 데이터 규모가 일정할 때 스케줄링 오버헤드를 최소화한다. 반면 동적 모드에서는 실시간 모니터링 모듈이 각 코어의 CPU 사용률, 메모리 대역폭, 전력 소비 등을 수집하고, 비용 함수(예: 실행 시간 × 전력) 기반으로 작업을 재배치한다. 작업 재배치는 Hadoop의 TaskTracker와 통신하여 현재 실행 중인 컨테이너를 중단하고, 새로운 코어에 재시작하는 형태로 구현된다.
핵심 기술적 도전 과제로는 (①) 이기종 코어 간 데이터 이동 비용 최소화, (②) Map/Reduce 프레임워크와의 호환성 유지, (③) 전력 관리 정책과 스케줄링 정책의 통합이 있다. 논문은 데이터 이동을 최소화하기 위해 데이터 로컬리티 기반 파티셔닝을 적용하고, HDFS 블록 위치와 코어 유형을 매핑하여 동일 코어 풀 내에서 최대한 로컬 데이터를 사용하도록 설계했다. 또한 Hadoop의 기존 인터페이스를 그대로 활용하면서 Scheduler 플러그인 형태로 구현함으로써 기존 클러스터 환경에 손쉽게 적용할 수 있게 했다. 전력 관리 측면에서는 각 코어의 DVFS(Dynamic Voltage and Frequency Scaling) 설정을 스케줄러가 제어하도록 하여, 부하가 낮은 순간에는 저전력 코어로 전환하고, 부하가 급증하면 고성능 코어를 활성화한다.
실험 결과는 (i) 전체 실행 시간이 평균 32 % 감소, (ii) 전력 소비가 27 % 절감되는 것을 보여준다. 특히 후보 집합 검증 단계에서 GPU‑전용 코어를 활용했을 때 가장 큰 가속 효과가 관찰되었다. 이러한 결과는 이기종 멀티코어와 적절한 스케줄링이 데이터 마이닝 워크로드에 큰 잠재력을 가지고 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기