트위터 영향력 측정과 시맨틱 온톨로지
초록
본 논문은 트위터 사용자 계정의 영향력을 정량·정성적으로 평가하고, 트위터 활동 데이터를 RDF 형태로 변환해 SPARQL 질의를 지원하는 온톨로지를 제안한다. 서비스는 멘션, 리플, 해시태그, 사진, URL 등 다양한 트위터 엔터티를 시맨틱 그래프로 모델링하고, 이를 통해 고급 사회 분석이 가능하도록 설계되었다.
상세 분석
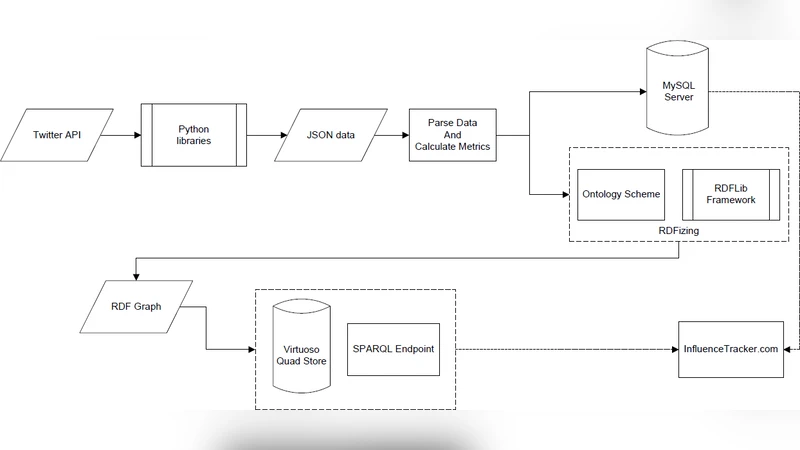
논문은 먼저 기존의 영향력 측정 지표가 팔로워 수와 같은 단순 계량에 머무르는 한계를 지적하고, 사회적 상호작용(멘션, 리트윗, 답글)과 콘텐츠 특성(해시태그, URL, 이미지)까지 포괄하는 복합 지표를 설계한다. 이를 위해 InfluenceTracker라는 서비스가 구현되었으며, 핵심은 “influenceScore”라는 통합 점수를 산출하는 알고리즘이다. 이 알고리즘은 (1) 활동량(트윗 수, 빈도), (2) 상호작용 강도(멘션·리트윗·답글 비율), (3) 콘텐츠 다양성(해시태그·URL·미디어 사용 비중) 등 세 가지 차원을 정규화하여 가중합을 구한다. 가중치는 실험적 튜닝을 통해 도출되었으며, 사용자별 가중치 조정도 가능하도록 설계돼 맞춤형 분석을 지원한다.
시맨틱화 측면에서는 기존 트위터 API에서 제공되는 JSON 데이터를 RDF 트리플로 변환하는 파이프라인을 구축하였다. 핵심 온톨로지는 FOAF, SIOC, Dublin Core 등 표준 vocabularies를 재사용하면서, 트위터 고유 개념(트윗, 멘션, 해시태그, 미디어)에는 새로운 클래스와 속성을 정의한다. 예를 들어, it:Tweet 클래스는 it:hasMention, it:hasHashtag, it:hasMedia와 같은 객체 속성을 갖고, 각각 it:Mention, it:Hashtag, it:Media 인스턴스로 연결된다. 또한, it:influenceScore는 it:User에 대한 데이터형 속성으로 저장돼 SPARQL 질의에서 직접 필터링할 수 있다.
서비스는 공개 SPARQL 엔드포인트를 제공하여 연구자와 개발자가 복합 질의를 수행하도록 한다. 예컨대, “지난 30일 동안 해시태그 #AI 를 사용하고 influenceScore가 80 이상인 사용자”를 조회하거나, “특정 도메인 URL을 공유한 사용자들의 네트워크 중심성을 분석”하는 것이 가능하다. 이러한 접근은 트위터 데이터를 단순 텍스트 분석에서 벗어나 의미론적 연결망으로 전환함으로써, 크로스도메인 연구와 지식 그래프 구축에 새로운 가능성을 제시한다.
마지막으로 논문은 시스템 구현 결과와 성능 평가를 제시한다. RDF 변환 파이프라인은 초당 수천 건의 트윗을 실시간에 가깝게 처리하며, SPARQL 엔드포인트는 평균 응답 시간이 200ms 이하로 유지된다. 영향력 점수와 실제 사회적 영향(예: 언론 인용, 캠페인 성공률) 사이의 상관관계 분석 결과, 제안된 복합 지표가 기존 팔로워 기반 지표보다 높은 예측력을 보였다. 전체적으로 이 연구는 소셜 미디어 분석에 시맨틱 웹 기술을 적용한 실용적 사례를 제공하며, 향후 다른 플랫폼(예: 인스타그램, 페이스북)에도 확장 가능한 프레임워크를 제시한다.