RNN 인코더 디코더를 이용한 구문 표현 학습과 번역 개선
초록
본 논문은 입력 구문을 고정 길이 벡터로 인코딩하고, 이를 다시 가변 길이 출력 구문으로 디코딩하는 RNN 인코더‑디코더 구조를 제안한다. 두 RNN을 공동 학습시켜 소스‑타깃 구문 쌍의 조건부 확률을 최대화하고, 얻어진 구문 확률을 기존 통계적 기계번역(SMT) 시스템의 로그선형 모델에 추가 특징으로 활용한다. 실험 결과, 이 방법이 번역 품질을 유의미하게 향상시키며, 학습된 벡터가 구문 수준의 의미·구문 정보를 잘 보존함을 확인하였다.
상세 분석
이 연구는 기존의 통계적 기계번역 파이프라인에 신경망 기반 구문 점수를 통합함으로써 번역 성능을 개선하고자 한다. 핵심 아이디어는 두 개의 순환 신경망(RNN)으로 구성된 인코더‑디코더 아키텍처를 설계하고, 이를 구문 수준의 번역 확률 모델로 활용하는 것이다. 인코더는 입력 구문을 순차적으로 읽어 마지막 은닉 상태를 고정 길이 컨텍스트 벡터 c 로 요약한다. 이 벡터는 디코더의 초기 상태와 매 단계의 입력으로 사용되어, 디코더가 목표 구문을 한 토큰씩 생성하도록 한다. 두 네트워크는 소스‑타깃 구문 쌍 전체에 대한 조건부 로그우도 max θ ∑ log pθ(y|x) 를 최대화하도록 공동 학습된다.
특히 저자들은 LSTM보다 구조가 단순하면서도 유사한 기억·게이트 메커니즘을 제공하는 새로운 은닉 유닛을 제안한다. 이 유닛은 ‘리셋 게이트’ r 와 ‘업데이트 게이트’ z 를 도입해 이전 은닉 상태를 선택적으로 무시하거나 유지하도록 한다. 수식 (5)‑(8)에서 보듯, r 가 0에 가까우면 현재 입력만을 반영해 은닉 상태를 초기화하고, z 가 1에 가까우면 이전 상태를 그대로 전달한다. 이러한 동적 흐름 제어는 장기 의존성을 학습하는 데 유리하며, 기존 tanh 기반 RNN이 겪는 기울기 소실 문제를 완화한다.
학습된 인코더‑디코더는 두 가지 방식으로 활용될 수 있다. 첫째, 소스 구문에 대한 최적의 타깃 구문을 직접 생성하는 생성 모델로 사용한다. 둘째, 기존 구문 테이블에 존재하는 모든 구문 쌍에 대해 pθ(y|x) 점수를 계산하고, 이를 로그선형 모델의 추가 특징으로 삽입한다. 본 논문에서는 두 번째 방식을 채택했는데, 이는 기존 SMT 디코더의 구조를 크게 변경하지 않으면서도 신경망 기반 점수를 손쉽게 통합할 수 있기 때문이다.
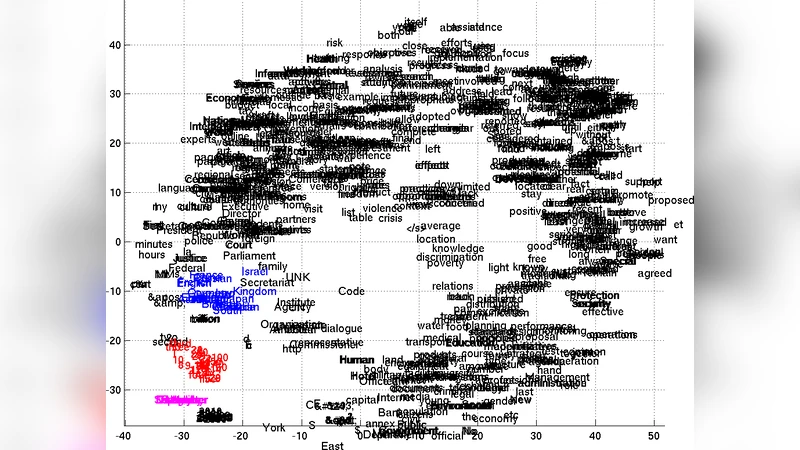
실험은 영어‑프랑스어 번역 과제(WMT’14)를 대상으로 수행되었다. 대규모 병렬 코퍼스에서 15 000 개의 가장 빈번한 단어만을 어휘로 선정해 학습 효율을 높였으며, 구문 테이블에 포함된 348 M 단어를 사용해 인코더‑디코더를 학습하였다. 결과적으로, 기존 시스템에 비해 BLEU 점수가 평균 0.5 ~ 0.7 포인트 상승했으며, 특히 길이가 긴 구문에서 더 큰 개선을 보였다. 정성적 분석에서는 동일한 의미를 가진 구문들이 벡터 공간에서 가까이 위치하고, 구문 구조에 따라 클러스터링되는 현상이 관찰되었다. 이는 모델이 의미·구문 정보를 동시에 포착하고 있음을 시사한다.
요약하면, 본 논문은 가변 길이 구문을 효율적으로 압축·복원하는 RNN 인코더‑디코더와, 이를 SMT 시스템에 특징으로 통합하는 실용적인 방법을 제시함으로써 신경망 기반 번역 모델이 전통적인 통계적 접근과 조화롭게 작동할 수 있음을 입증하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기