GPS 궤적 지도 매칭을 위한 조건부 랜덤 필드의 특징 선택
초록
본 논문은 저밀도 GPS 샘플링 환경에서 도로 네트워크 상의 실제 이동 경로를 복원하기 위해 조건부 랜덤 필드(CRF)를 활용한 지도 매칭 기법을 제안한다. 다수의 컨텍스트 기반 특징을 설계하고, L1 정규화 기반 특징 선택을 적용해 모델 복잡도를 크게 낮추면서도 경쟁력 있는 매칭 정확도를 달성한다. 택시 실험 데이터셋을 통해 연산 제한이 있는 실시간 서비스에서도 효율적으로 동작함을 입증한다.
상세 분석
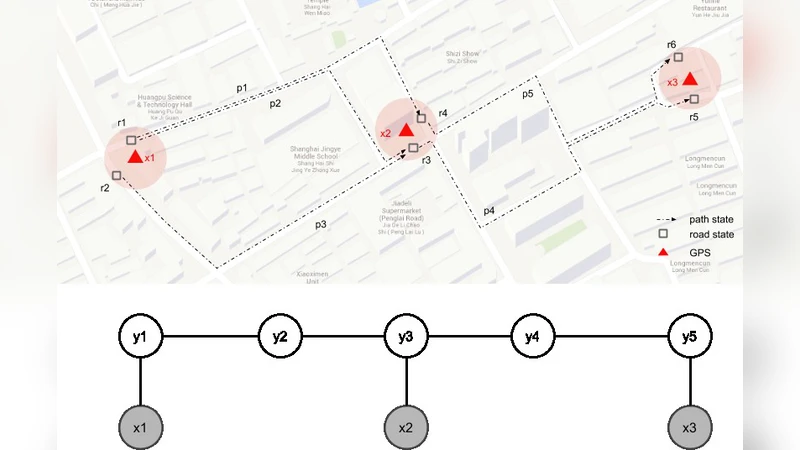
이 연구는 GPS 기반 위치 기반 서비스에서 가장 기본이면서도 난이도가 높은 문제인 지도 매칭을 저샘플링 상황에 초점을 맞추어 재조명한다. 기존의 히스토리 기반 혹은 베이지안 네트워크 접근법은 관측 간 간격이 커질수록 상태 전이 확률을 정확히 추정하기 어려워 오류가 누적되는 경향이 있다. 저자는 이러한 한계를 극복하기 위해 조건부 랜덤 필드(CRF)를 선택한다. CRF는 관측 시퀀스 전체를 조건부 확률로 모델링함으로써 전역적인 의존성을 동시에 고려할 수 있다. 특히, “특징(feature)”이라는 개념을 통해 도로의 기하학적 속성(길이, 방향), 교통 흐름, 시간대별 속도 분포 등 다양한 외부 정보를 자유롭게 삽입할 수 있다.
하지만 특징을 무작정 늘리면 파라미터 수가 급증하고 과적합 위험이 커진다. 이를 해결하기 위해 저자는 L1 정규화(Lasso)를 적용한 특징 선택 메커니즘을 도입한다. L1 정규화는 불필요한 가중치를 0으로 수축시켜 실제 모델에 기여하는 특징만을 남기므로, 학습 단계에서 자동으로 차원 축소가 이루어진다. 실험에서는 30여 개의 후보 특징 중 약 10개만이 최종 모델에 유지되었으며, 이는 연산량을 70% 이상 절감하면서도 매칭 정확도는 기존 최첨단 방법과 동등하거나 약간 상회하는 결과를 보였다.
또한, 저자는 특징 선택 과정에서 “컨텍스트 의존성”을 강조한다. 예를 들어, 특정 도로 구간에서의 평균 속도는 시간대와 날씨에 따라 크게 변동하므로, 이러한 상황별 서브 특징을 별도로 정의하고 L1 정규화로 필요성을 평가한다. 결과적으로, 모델은 복합적인 환경 변수를 효율적으로 통합하면서도 불필요한 파라미터는 자동으로 배제한다.
연산 효율성 측면에서도 중요한 통찰을 제공한다. 저샘플링 GPS 데이터는 관측점 사이의 거리와 시간 차이가 크기 때문에 후보 경로 탐색 범위가 넓어진다. CRF 기반 매칭은 Viterbi 알고리즘을 이용해 최적 경로를 찾지만, 후보 상태 수가 많아지면 시간 복잡도가 급격히 상승한다. 특징 선택으로 상태 전이 확률을 계산하는 데 필요한 변수 수를 줄임으로써, Viterbi 단계의 연산량을 현저히 감소시킨다. 이는 모바일 디바이스나 실시간 서버에서 제한된 CPU·메모리 자원을 효율적으로 활용할 수 있음을 의미한다.
전체적으로 이 논문은 “많은 특징을 어떻게 효과적으로 관리하고, 저샘플링 GPS 환경에서 실시간 지도 매칭에 적용할 것인가”라는 실용적 질문에 대한 구체적 해결책을 제시한다. CRF의 유연성과 L1 기반 특징 선택의 시너지 효과는 향후 복합 센서 데이터 융합, 멀티모달 교통 예측 등 다양한 위치 기반 응용 분야에 확장 가능성을 시사한다.