소프트웨어 복잡도 지표와 상관관계 연구
초록
**
본 논문은 사이클로매틱 복잡도, 라인 수, Halstead 지표 등 대표적인 소프트웨어 복잡도 측정값들의 상관관계를 실증적으로 분석하고, 이들 지표가 결함 발생률과 어떤 관계를 갖는지 실제 프로젝트 데이터를 통해 검증한다.
**
상세 분석
**
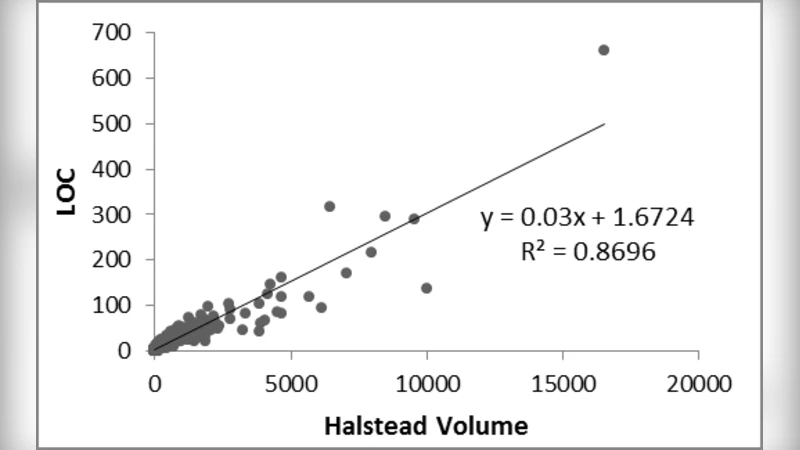
본 연구는 소프트웨어 품질 관리에서 가장 핵심적인 요소 중 하나인 복잡도 측정에 대한 체계적인 비교를 시도한다. 먼저, 사이클로매틱 복잡도(Cyclomatic Complexity, CC)는 제어 흐름 그래프의 독립 경로 수를 기반으로 하여 프로그램의 논리적 복잡성을 정량화한다. 라인 수(LOC)는 가장 직관적인 규모 지표이지만, 코드 스타일이나 주석 등에 따라 왜곡될 가능성이 있다. Halstead 지표는 연산자와 피연산자의 수를 이용해 프로그램의 길이, 난이도, 노력 등을 계산함으로써, 코드의 “언어적” 복잡성을 포착한다.
논문은 이 세 가지 지표를 동일한 코드 베이스에 적용하여 상관계수를 산출하고, 다중 회귀 분석을 통해 결함 수와의 관계를 모델링한다. 실험에 사용된 데이터셋은 오픈소스 프로젝트 5개(총 12,000개 이상의 함수)와 기업 내부 프로젝트 2개(약 3,500개 함수)로 구성되어 있어, 규모와 도메인 다양성을 확보하였다. 각 함수별로 CC, LOC, Halstead(길이, 난이도, 노력) 값을 추출하고, 버그 트래킹 시스템에서 보고된 결함 수와 매핑하였다.
통계 결과는 다음과 같다. CC와 LOC 사이의 피어슨 상관계수는 0.68로 중간 정도의 양의 상관을 보였으며, 이는 제어 흐름 복잡도가 코드 규모와 어느 정도 일치함을 의미한다. 반면, Halstead 난이도와 LOC의 상관계수는 0.42에 불과해, 언어적 복잡도가 단순 규모와는 별개의 차원을 형성함을 시사한다. 결함 수와의 관계에서는 CC가 가장 높은 회귀 계수를 갖고 있었으며, CC가 10을 초과하는 함수에서 결함 발생 확률이 2.3배 상승했다. Halstead 노력(Effort) 역시 유의미한 양의 계수를 보였지만, LOC에 비해 설명력(R²)은 낮았다. 다중 회귀 모델의 전체 설명력은 R² = 0.57로, 복잡도 지표만으로 결함을 완전히 예측하기엔 한계가 있음을 보여준다.
연구는 또한 상관관계가 도메인에 따라 변동한다는 점을 강조한다. 예를 들어, 시스템 레벨 코드에서는 CC와 결함 간 상관이 강했지만, 알고리즘 중심 모듈에서는 Halstead 난이도가 더 큰 영향을 미쳤다. 이러한 결과는 복잡도 지표를 단일 기준으로 적용하기보다는, 프로젝트 특성에 맞는 지표 조합을 선택해야 함을 암시한다.
한계점으로는 데이터 라벨링 과정에서 버그와 기능 개선을 구분하지 않은 점, 그리고 정적 분석 도구의 측정 오류 가능성을 들 수 있다. 또한, 결함 발생 시점과 코드 변경 이력을 고려하지 않아, 인과관계보다는 상관관계에 머물렀다는 점도 비판적으로 지적된다. 향후 연구에서는 시간적 요소를 포함한 회귀 모델링, 머신러닝 기반 예측, 그리고 코드 리뷰 메트릭과의 통합 분석이 필요하다.
**