빅데이터 기술을 활용한 사회과학 연구의 가치
초록
본 논문은 트위터와 같은 대규모 소셜 미디어 데이터를 수집·저장·처리하기 위해 오픈소스 빅데이터 스택을 적용한 사례를 제시한다. 데이터의 양·속도·다양성을 고려한 파이프라인 설계와 단계별 ‘퍼널링’ 기법을 통해 원시 데이터를 분석 가능한 형태로 전환하고, 이를 통해 사회 정보 지형을 시각화한다. 연구는 확장 가능한 인프라가 사회과학 연구에 제공하는 실질적 가치를 입증한다.
상세 분석
이 논문은 소셜 네트워크 분석이 요구하는 ‘3V’(Volume, Velocity, Variety) 특성을 충족시키기 위해 Hadoop 에코시스템(HDFS, MapReduce), Apache Spark, NoSQL 데이터베이스(Cassandra, MongoDB) 등 오픈소스 기술을 조합한 통합 아키텍처를 설계하였다. 데이터 수집 단계에서는 Twitter Streaming API와 OAuth 인증을 이용해 실시간 트윗을 1초당 수천 건 규모로 확보하고, Kafka와 같은 메시지 큐를 통해 수집된 스트림을 분산 저장소에 비동기적으로 전달한다. 저장 단계에서는 HDFS에 원시 JSON 로그를 그대로 적재하고, 동시에 Cassandra에 키‑밸류 형태로 인덱싱하여 빠른 조회와 시간 기반 파티셔닝을 가능하게 한다.
처리 단계에서는 Spark Streaming을 활용해 실시간 필터링, 토큰화, 언어 감지, 정서 분석 등을 수행한다. 여기서 ‘퍼널링’ 접근법이 핵심 역할을 한다. 초기 단계에서 불필요한 메타데이터와 스팸 계정을 제거하고, 이후 단계에서 해시태그·언급·위치 정보 등 관계형 데이터를 추출한다. 이렇게 단계별로 데이터 양을 10~100배 축소함으로써 분석 비용을 크게 절감하고, 변동성이 높은 소셜 데이터의 ‘Veracity’ 문제를 정제 알고리즘으로 보완한다.
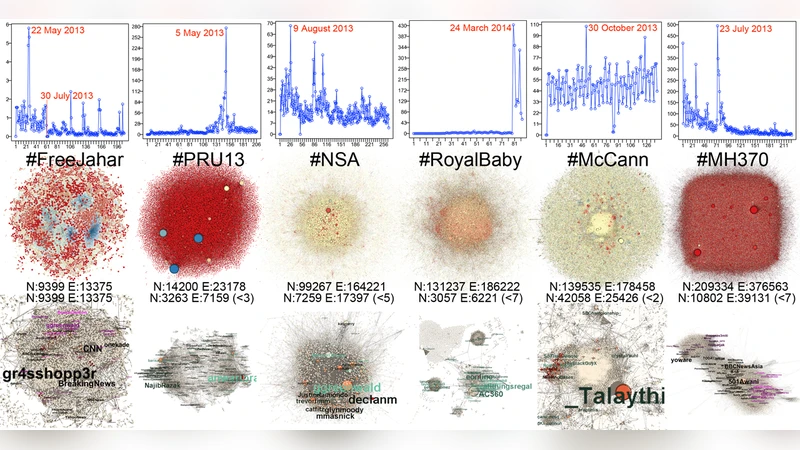
시각화 모듈은 Gephi와 D3.js를 연동해 네트워크 그래프, 시간 흐름 차트, 지리적 히트맵 등을 동적으로 생성한다. 특히, 네트워크 중심성 지표와 커뮤니티 탐지 알고리즘(Louvain)을 결합해 ‘사회 정보 지형’이라 명명한 다차원 맵을 구축함으로써 연구자는 특정 이슈가 어떻게 확산되고, 어떤 서브커뮤니티가 핵심 역할을 하는지 직관적으로 파악할 수 있다.
기술적 관점에서 주목할 점은 (1) 오픈소스 스택을 활용해 비용 효율적인 클라우드 배포가 가능하다는 점, (2) 데이터 파이프라인이 모듈화돼 새로운 소스(예: Instagram, Reddit) 추가가 용이하다는 점, (3) Spark와 Cassandra의 결합이 실시간 분석과 대용량 영구 저장을 동시에 만족한다는 점이다. 또한, 데이터 품질 관리 측면에서 ‘데이터 버전 관리’를 Git‑like 메타데이터 레이어로 구현해 실험 재현성을 확보한 점도 의미 있다.
결과적으로, 본 연구는 빅데이터 인프라가 사회과학 연구에 제공하는 ‘스케일러빌리티’와 ‘유연성’이 단순한 기술 시연을 넘어 실제 현상 탐지와 정책 인사이트 도출에 기여할 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기