상한 확률 논리를 위한 새로운 논리 체계
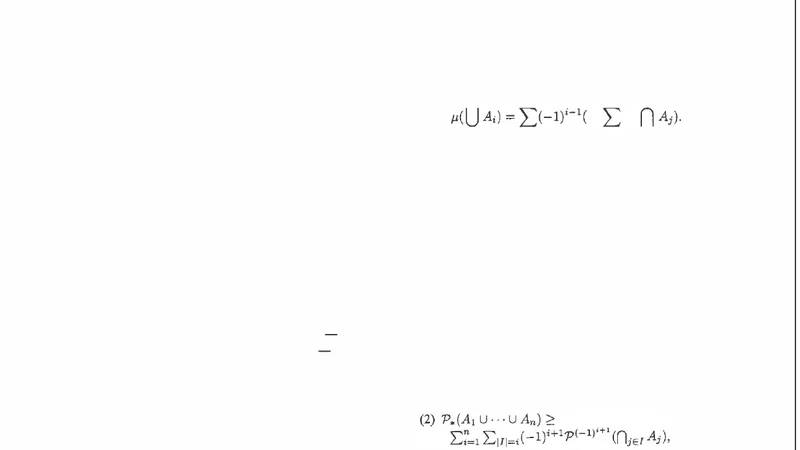
초록
이 논문은 사건의 불확실성을 확률 측정들의 집합으로 모델링하고, 각 사건에 대해 확률 구간을 할당하는 상한 확률(upper probability) 개념을 다룬다. 저자들은 이러한 불확실성을 표현하기 위한 명제 논리를 정의하고, 완전하고 sound한 공리 체계를 제시한다. 또한 만족 가능성 문제를 분석하여, 이 논리의 SAT 문제는 전통적인 명제 논리와 동일하게 NP‑complete임을 증명한다.
상세 분석
논문은 먼저 상한 확률이라는 개념을 소개한다. 전통적인 확률론에서는 단일 확률 측정 μ가 사건 A에 대해 정확한 값 μ(A)를 부여한다. 그러나 실제 상황에서는 정보가 불완전하거나 모호하여 하나의 측정만으로는 충분하지 않을 때가 많다. 이를 해결하기 위해 확률 측정들의 집합 𝔓를 고려하고, 각 사건 A에 대해 가능한 확률값들의 최소와 최대, 즉 하한 l(A)=inf{μ(A):μ∈𝔓}와 상한 u(A)=sup{μ(A):μ∈𝔓}를 정의한다. 이러한 구간은 사건의 불확실성을 직접적으로 나타내며, ‘상한 확률’이라는 용어는 u(A)를 가리킨다.
다음으로 저자들은 상한 확률을 다루는 명제 논리를 설계한다. 언어는 전통적인 명제 변수와 논리 연산자(∧, ∨, ¬)에 더해, 상한 확률 연산자를 도입한다. 구체적으로, 식 “P≥α(φ)”는 φ라는 명제가 최소 α의 확률을 갖는다는 의미이며, “P≤β(φ)”는 φ의 확률이 β 이하임을 나타낸다. 이러한 연산자는 구간 표현을 가능하게 하여, φ에 대한 불확실성을