연관 규칙과 의존 구문 기반 텍스트 분류 및 의미 확장
초록
본 논문은 텍스트 분류를 위해 연관 규칙 기반 클래스 연관 규칙(CAR)을 활용하고, 문장 수준에서 의존 구문 정보를 이용한 단어 선택(pruning)과 WordNet 하이퍼님을 이용한 의미 확장(hyperonymization)을 결합한다. tf‑idf 기반 절삭과 비교하여 의존 구문 절삭이 정확도·재현율 모두에서 우수함을 보이며, 하이퍼님 적용은 재현율을 높이지만 정밀도는 약간 감소한다. 7개 토픽의 Reuters 데이터셋에서 1,000개 규칙을 고정하고 10‑fold 교차 검증으로 평가하였다.
상세 분석
이 연구는 텍스트 분류 문제를 고전적인 “bag‑of‑words” 모델의 한계에 주목하고, 규칙 기반 접근법의 가독성과 해석 가능성을 살리기 위해 클래스 연관 규칙(CAR)을 핵심 분류기로 채택한다. CAR은 아이템 집합(여기서는 단어)과 클래스 라벨을 쌍으로 하는 트랜잭션이며, 최소 지원(support)과 최소 신뢰도(confidence) 기준을 만족하는 경우에만 규칙으로 채택된다. 규칙 수가 급격히 늘어나는 것을 방지하기 위해 두 단계의 전처리 과정을 도입한다. 첫 번째는 문장 수준에서의 pruning이다. 기존 연구에서는 단어 빈도나 tf‑idf 점수를 이용해 상위 N개의 단어만 남겼지만, 본 논문은 의존 구문 트리를 활용한다. 각 문장을 Stanford Dependency Parser로 분석하고, 명사 주어(nsubj), 직접 목적어(dobj), 전치사구(prep) 등 의미 중심의 의존 관계를 갖는 토큰만을 선택한다. 이렇게 하면 문장의 핵심 의미를 담당하는 단어들만 남게 되어 아이템 집합의 차원을 크게 줄일 수 있다. 두 번째는 hyperonymization이다. WordNet에서 각 단어의 가장 빈번한 상위 의미(하이퍼님)를 찾아 원 단어를 대체한다. 하이퍼님 체인 중 가장 높은 로그 빈도(lf)를 가진 경로를 선택하고, i‑번째 상위 하이퍼님을 h_i(w)라 정의한다. 이 과정은 희소한 단어를 보다 일반적인 의미로 추상화함으로써 규칙의 지원도를 높이고, 클래스 간 구분력을 강화한다.
학습 단계에서는 문장을 lemmatize → prune → hyperonymize 순으로 처리한 뒤, Apriori 알고리즘을 적용해 CAR 집합 R을 생성한다. 각 규칙은 (아이템 집합, 클래스, 신뢰도) 형태이며, 신뢰도는 해당 아이템 집합이 등장했을 때 실제 클래스가 일치하는 비율로 계산된다. 분류 단계에서는 새로운 문서 D의 각 문장 S에 대해 아이템 집합이 포함된 규칙을 찾고, 가장 높은 신뢰도를 가진 규칙을 선택한다. 문서 수준에서는 모든 문장에 대한 규칙의 신뢰도를 합산해 가장 큰 합을 가진 클래스를 최종 예측값으로 채택한다. 이때 예측 품질을 평가하기 위해 variety(β)(예측에 사용된 클래스 수)와 dispersion(Δ)(최고·최저 신뢰도 차)라는 두 메트릭을 도입한다.
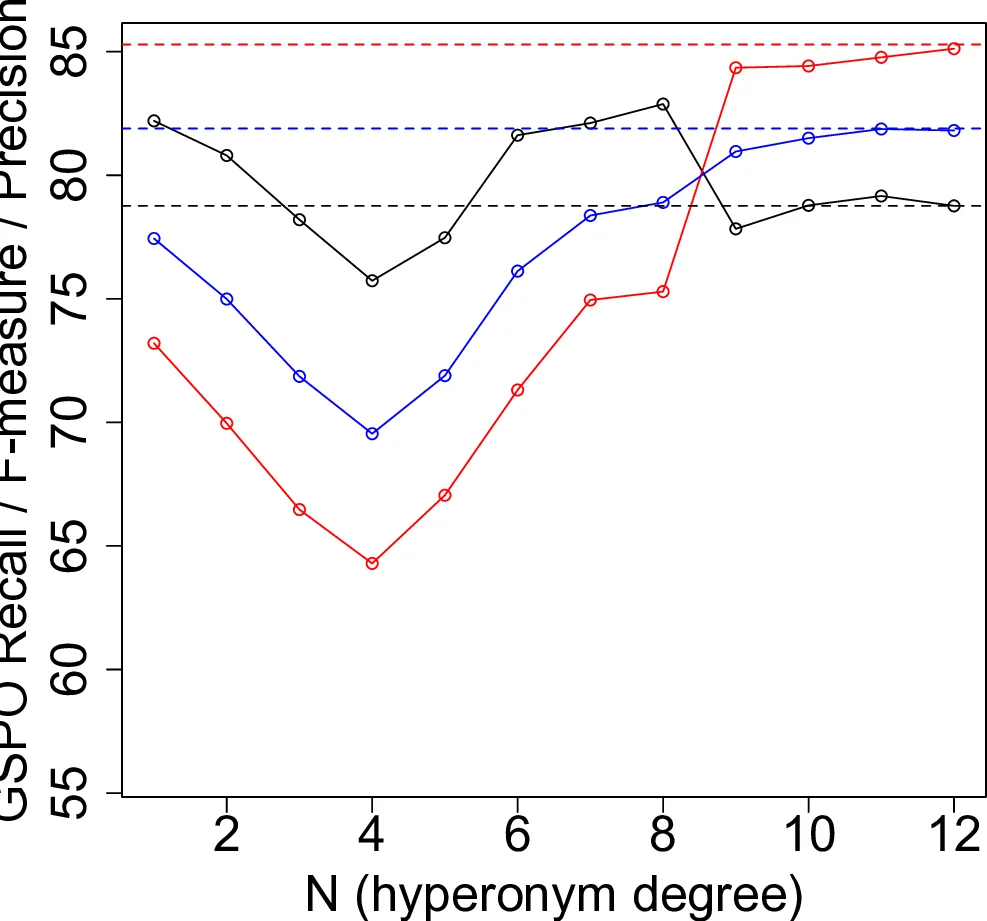
실험은 Reuters-21578 코퍼스에서 7개 토픽(GSPO, E12, GPOL, GVIO, GDIP, GCRIM, GJOB)을 선택하고, 각 토픽당 1,000개의 가장 긴 문서를 추출해 총 7,000문서를 구성하였다. 문장은 Stanford Dependency Parser로 분석하고, tf‑idf 기반 절삭, 의존 구문 절삭, 의존 구문 + 하이퍼님 절삭 세 가지 전략을 비교했다. 규칙 수는 가독성을 위해 1,000개(±2)로 고정하고, 최소 지원·신뢰도 파라미터는 F‑measure가 최대가 되도록 자동 탐색하였다. 결과는 의존 구문 절삭이 tf‑idf 대비 평균 정밀도(P)와 재현율(R) 모두에서 약 35%p 향상을 보였으며, 하이퍼님 적용은 재현율을 추가로 24%p 상승시키지만 정밀도는 약 1%p 감소하였다. 또한 variety와 dispersion 지표는 의존 구문 기반이 더 낮은 값을 보여, 규칙이 보다 집중되고 예측이 안정적임을 시사한다. 전반적으로 본 논문은 규칙 기반 텍스트 분류에서 해석 가능성을 유지하면서도, 구문론적 정보와 의미론적 일반화를 결합함으로써 성능을 실질적으로 개선할 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기