객체 시각 모델 최신 동향 한눈에
초록
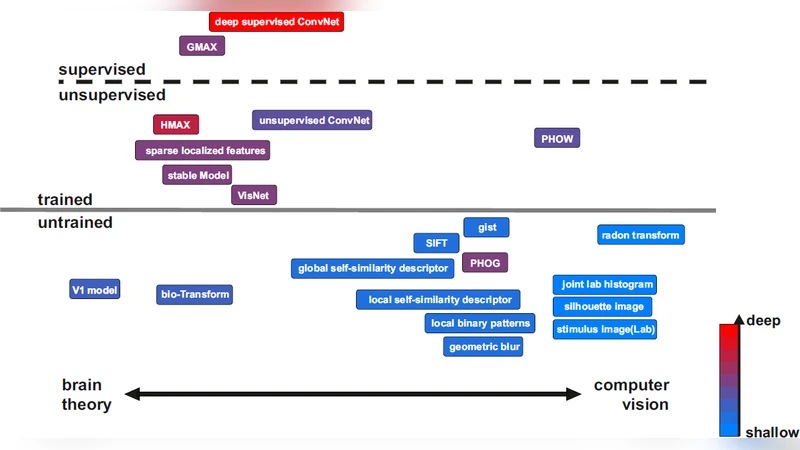
본 논문은 객체 인식을 위한 시각 모델들을 감독 학습, 비감독 학습, 완전 하드와이어드 방식으로 구분하고, 깊이와 생물학적 영감 여부에 따라 계층 구조를 비교한다. 최근 대규모 이미지 데이터로 학습되는 딥 네트워크와 변형 모델들을 포함해 각 모델의 핵심 연산 원리와 장단점을 직관적으로 정리한다.
상세 분석
논문은 먼저 객체 시각 모델을 크게 세 축으로 분류한다. 첫 번째 축은 학습 방식이다. 완전 하드와이어드 모델은 인간이 설계한 필터(예: Gabor, SIFT, HMAX)로 구성돼 사전 학습이 필요 없으며, 저차원 특징을 빠르게 추출한다. 그러나 표현력이 제한적이고 복잡한 변형에 취약하다. 두 번째 축은 감독 학습 모델이다. 대표적인 예가 AlexNet, VGG, ResNet 등 깊은 컨볼루션 신경망(CNN)으로, 수백만 이미지와 라벨을 통해 계층적 특징을 자동 학습한다. 초기 층은 에지와 색상, 중간 층은 텍스처와 패턴, 최상위 층은 객체 부품과 전체 형태를 코딩한다. 이러한 모델은 높은 정확도를 보이지만 대규모 라벨 데이터와 연산 자원이 필수이며, 학습 과정이 불투명해 생물학적 해석이 어렵다. 세 번째 축은 비감독·자기지도 학습 모델이다. SimCLR, MoCo, BYOL 같은 대비 학습 방법은 이미지 쌍을 변형해 긍정/부정 샘플을 생성하고, 특징 공간을 정규화한다. 최근 CLIP은 이미지와 텍스트를 동시에 학습해 다중 모달 의미를 내재한다. 이러한 모델은 라벨 없이도 강력한 표현을 얻으며, 전이 학습 시 뛰어난 일반화를 보인다.
다음으로 모델의 깊이와 계층 구조를 살핀다. 전통적인 HMAX는 45계층으로 제한돼 인간 시각 피질 V1‑V4에 대응한다. 반면 현대 CNN은 20150계층을 갖고, 잔차 연결이나 스킵 연결을 통해 기울기 소실 문제를 해결한다. Vision Transformer(ViT)는 패치 임베딩을 토큰화하고 자체 주의 메커니즘을 적용해 전통적인 컨볼루션을 대체한다. ViT는 전역적인 상관관계를 한 번에 포착하지만, 위치 정보 손실과 대규모 데이터 요구가 단점이다.
생물학적 타당성 측면에서, 초기 계층의 Gabor‑유사 필터와 CNN 초반 필터는 시각 피질의 반응과 유사성을 보인다. 그러나 깊은 층에서의 비선형 변환과 풀링은 뇌의 복합적인 피드백·전위 연결을 완전히 모사하지 못한다. 최근 연구는 역전파 대신 Hebbian 학습이나 스파이킹 뉴런 모델을 도입해 생물학적 구현 가능성을 탐색한다.
마지막으로 실용적 고려사항을 논한다. 하드와이어드 모델은 임베디드 시스템이나 저전력 디바이스에 적합하고, 딥 모델은 클라우드·GPU 환경에서 최고의 성능을 낸다. 비감독 모델은 라벨 비용을 절감하면서도 다양한 도메인에 전이 가능해 데이터가 부족한 상황에 유리하다. 전체적으로 논문은 모델 선택 시 정확도, 연산 비용, 데이터 가용성, 생물학적 해석 가능성 등을 균형 있게 평가할 것을 권고한다.