확률적 프로그래밍을 위한 새로운 컴파일 타깃, Probabilistic C
Probabilistic C는 POSIX fork, mutex, 공유 메모리와 같은 표준 운영체제 기능만을 이용해 확률적 프로그램의 전방 추론(Sequential Monte Carlo, Particle MCMC)을 구현할 수 있는 C 기반 중간표현(IR)이다. 기존 컴파일러와 OS 라이브러리만으로 기계어로 컴파일되며, 가우시안 평균 추정, 은닉 마코프 모델, 무한 가우시안 혼합 등 다양한 베이지안 모델을 효율적으로 실행한다.
저자: Brooks Paige, Frank Wood
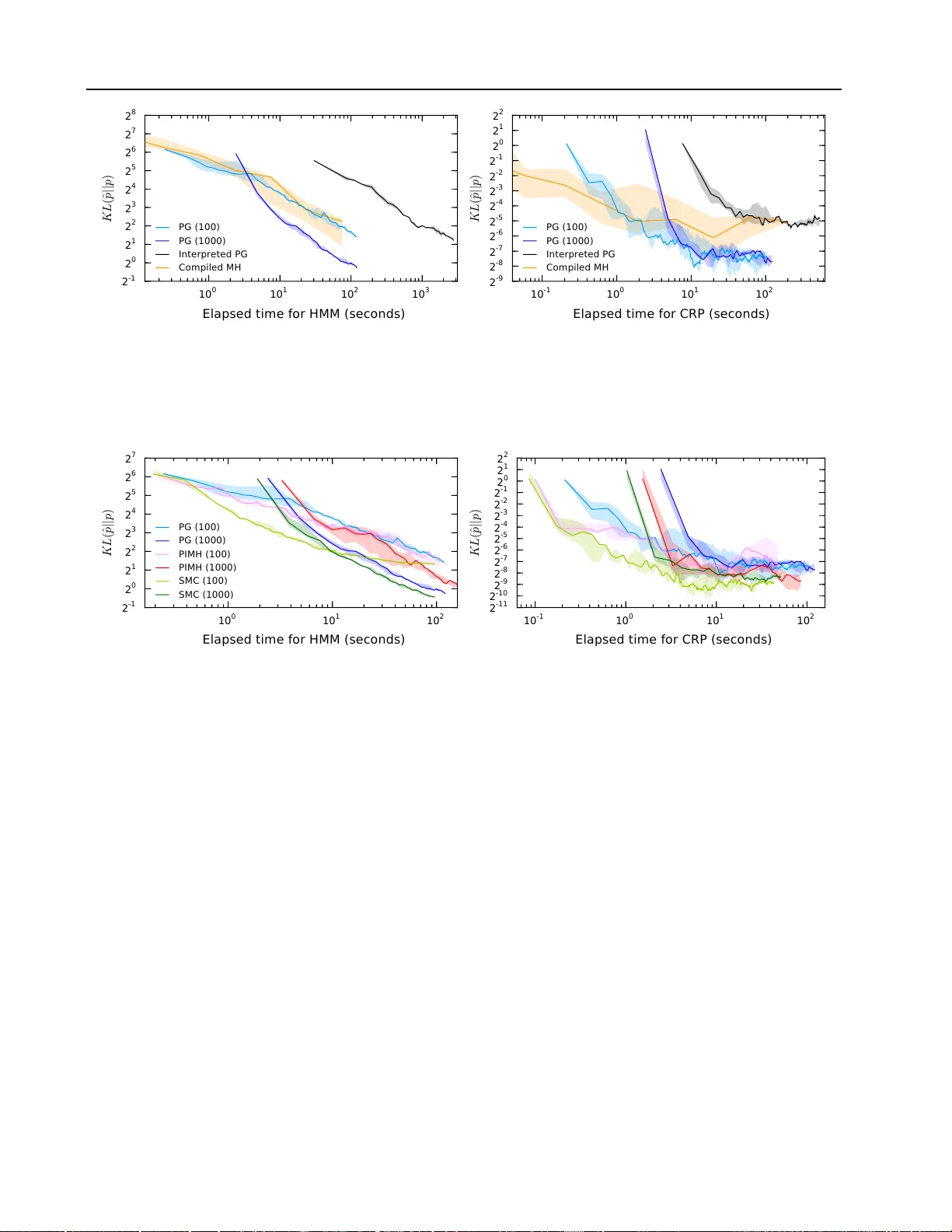
본 논문은 확률적 프로그래밍 언어의 추론을 기존 운영체제와 컴파일러 인프라만으로 구현할 수 있는 새로운 중간표현, Probabilistic C를 제안한다. 서론에서는 컴파일을 소스‑투‑소스 변환으로 정의하고, C 언어 라이브러리를 이용해 확률적 프로그램을 표현하는 방법을 소개한다. 핵심 라이브러리는 두 가지 매크로와 함수, 즉 `observe`와 `predict`를 제공한다. `observe`는 로그우도 값을 받아 현재 실행 트레이스에 대한 가중치를 업데이트하고, `predict`는 관심 변수의 값을 출력한다. 또한, `memoize`와 같은 부가 기능을 통해 스토캐스틱 메모이제이션을 지원한다.
논문은 세 가지 예제 프로그램을 통해 Probabilistic C의 표현력을 시연한다. 첫 번째 예제는 두 개의 관측값을 가진 가우시안 평균 추정 모델로, `normal_rng`와 `normal_lnp` 함수를 사용해 사전과 관측우도를 정의하고, `observe`와 `predict`로 추론 과정을 기술한다. 두 번째 예제는 3개의 은닉 상태와 가우시안 방출을 갖는 은닉 마코프 모델(HMM)이다. 상태 전이 행렬과 초기 상태 분포를 정적 배열로 선언하고, 각 시간 단계에서 `discrete_rng`와 `normal_lnp`를 이용해 상태 전이와 관측을 수행한다. 세 번째 예제는 디리클레 프로세스를 기반으로 한 무한 가우시안 혼합 모델이다. 여기서는 `polya_urn_draw`, `memoize`, `mem_invoke` 등을 활용해 클러스터 할당을 동적으로 생성하고, 각 클러스터의 파라미터를 `normal_rng`와 `gamma_rng`로 샘플링한다.
핵심 기술은 운영체제 수준의 프로세스 포크와 동기화 메커니즘이다. 프로그램 실행 시 각 파티클은 독립적인 프로세스로 실행되며, `fork` 호출을 통해 현재 실행 상태를 복제한다. 복제는 copy‑on‑write 방식을 사용해 메모리 복사 비용을 최소화한다. 관측점마다 모든 파티클이 도달할 때까지 barrier가 설정되어, 각 파티클은 자신의 로그우도 가중치를 공유 메모리에 기록한다. 이후 ESS(Effective Sample Size)를 계산하고, 사전에 정의된 임계값(예: L/2) 이하이면 재샘플링을 수행한다. 재샘플링은 각 파티클이 생성할 자식 수 O를 공유 메모리에 저장하고, 파티클은 O에 따라 `fork`를 반복하거나 종료한다. 이 과정은 알고리즘 1에 상세히 기술되어 있으며, 병렬(프로세스 실행), 직렬(가중치 계산, ESS 평가), barrier(동기화) 단계가 명확히 구분된다.
추가로, 논문은 Particle Metropolis‑Hastings(PMH)와 같은 MCMC 변형을 설명한다. 한 번의 SMC 필터링 후 얻은 주변우도 추정값 \hat Z 를 이용해 새로운 파티클 집합을 제안 분포로 사용하고, MH 수락 확률 min(1, \hat Z' / \hat Z) 로 새로운 샘플을 받아들인다. 이는 고차원 베이지안 모델에서도 효율적인 탐색을 가능하게 한다.
시스템적 관점에서 Probabilistic C는 기존 C 컴파일러(gcc, clang 등)와 POSIX 라이브러리만으로 완전한 실행 파일을 생성한다. 따라서 새로운 하드웨어(예: GPU, ASIC)나 특수 OS 커널을 설계할 때도 동일한 IR을 그대로 이식할 수 있어, 시스템 연구자에게 최적화 가능성을 크게 열어준다. 그러나 현재는 고수준 확률 프로그래밍 언어를 자동으로 Probabilistic C로 변환하는 파이프라인이 부재하며, 사용자가 직접 C 코드로 모델을 작성해야 하는 진입 장벽이 존재한다. 또한, 프로세스 기반 병렬화는 대규모 파티클 수가 필요할 경우 운영체제의 프로세스/스레드 제한, 컨텍스트 스위칭 오버헤드, 공유 메모리 동기화 비용 등에 의해 성능이 제한될 수 있다.
결론적으로, 이 연구는 확률적 프로그래밍을 전통적인 시스템 소프트웨어 스택 위에 놓음으로써, 하드웨어 독립적인 최적화와 확장성을 동시에 추구한다는 점에서 의미가 크다. 향후 작업으로는 고수준 언어에서 Probabilistic C로의 자동 변환, 비‑POSIX 환경 지원, 그리고 프로세스 대신 경량 스레드나 GPU 커널을 활용한 구현이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기