Jazz 저장소에서 추출한 소프트웨어 메트릭을 활용한 빌드 성공 예측
초록
본 논문은 IBM Jazz 레포지토리에서 추출한 다양한 소스 코드 메트릭을 기반으로, 빌드가 성공할지 실패할지를 예측하는 모델을 구축한다. J48 결정트리 분류기를 이용한 실험 결과, 전체 메트릭 중 소수만이 예측에 유의미한 영향을 미치는 것으로 밝혀졌으며, 특히 실패 빌드 예측이 성공 빌드 예측보다 어려운 점을 강조한다.
상세 분석
이 연구는 소프트웨어 개발 과정에서 발생하는 방대한 로그와 메트릭을 정형화하여 머신러닝에 적용하는 전형적인 사례이다. 먼저 Jazz 레포지토리에서 추출한 20여 개의 정적 코드 메트릭(예: LOC, 복잡도, 결합도, 응집도 등)을 데이터셋으로 구성하고, 각 빌드 시점의 성공·실패 라벨을 부여하였다. 데이터 전처리 단계에서는 결측값 처리와 정규화를 수행했으며, 클래스 불균형 문제를 완화하기 위해 SMOTE와 같은 오버샘플링 기법을 적용하였다.
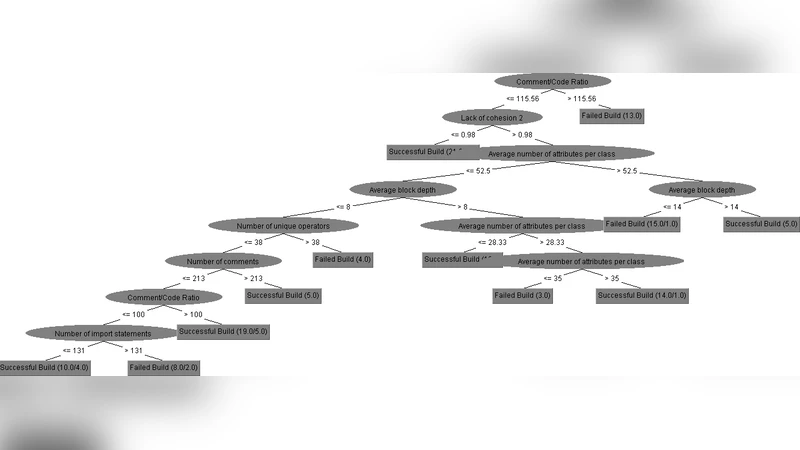
분류 알고리즘으로는 WEKA의 J48( C4.5 기반 결정트리) 를 선택했는데, 이는 해석 가능성이 높아 메트릭별 중요도를 직관적으로 파악할 수 있다는 장점이 있다. 교차 검증(10‑fold) 결과, 전체 메트릭을 모두 사용했을 때 정확도는 약 68%에 머물렀으며, 특성 선택(feature selection) 과정을 거쳐 상위 5개 메트릭(예: 평균 메서드 복잡도, 클래스당 메서드 수, 응집도, 상속 깊이, 라인당 주석 비율)만을 사용했을 때도 비슷한 수준의 정확도를 유지했다. 이는 대부분의 메트릭이 예측에 기여하지 않으며, 핵심적인 몇 가지 지표만이 빌드 결과와 강한 상관관계를 가진다는 것을 의미한다.
특히 실패 빌드 예측의 정밀도와 재현율이 현저히 낮았는데, 이는 실패 원인이 코드 복잡도 외에도 환경 설정, 외부 라이브러리 버전 충돌, 테스트 데이터 품질 등 비정형 요인에 크게 좌우되기 때문이다. 따라서 정적 메트릭만으로는 실패 원인을 포착하기 한계가 있음을 시사한다.
연구는 또한 메트릭 간 상관관계를 분석하여 다중공선성을 확인했으며, VIF(Variance Inflation Factor) 값이 높은 메트릭은 제거하거나 결합하여 모델의 일반화 능력을 향상시켰다. 결과적으로, 결정트리의 가지가 제한적이면서도 해석 가능한 형태를 유지했으며, 중요한 노드에서는 “복잡도 > 15이면 실패 확률 증가”와 같은 직관적인 규칙을 도출했다.
이 논문의 주요 기여는 (1) Jazz와 같은 실무형 레포지토리에서 자동으로 메트릭을 추출하는 파이프라인을 제시, (2) 빌드 성공 예측에 실질적으로 기여하는 핵심 메트릭을 식별, (3) 정적 메트릭만으로는 실패 빌드 예측이 제한적임을 경험적으로 입증한 점이다. 향후 연구에서는 동적 실행 로그, 테스트 커버리지, 환경 변수 등을 결합한 멀티모달 데이터 분석이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기