SMOTE 기반 소프트웨어 빌드 결과 예측 모델 연구
초록
본 논문은 데이터 스트림 마이닝과 SMOTE 과샘플링을 결합해 소스 코드 메트릭으로 빌드 성공·실패를 예측하는 의사결정트리 모델을 구축하고, 900건 이상의 빌드 데이터를 학습시켰을 때 80% 수준의 정확도를 달성했음을 보고한다.
상세 분석
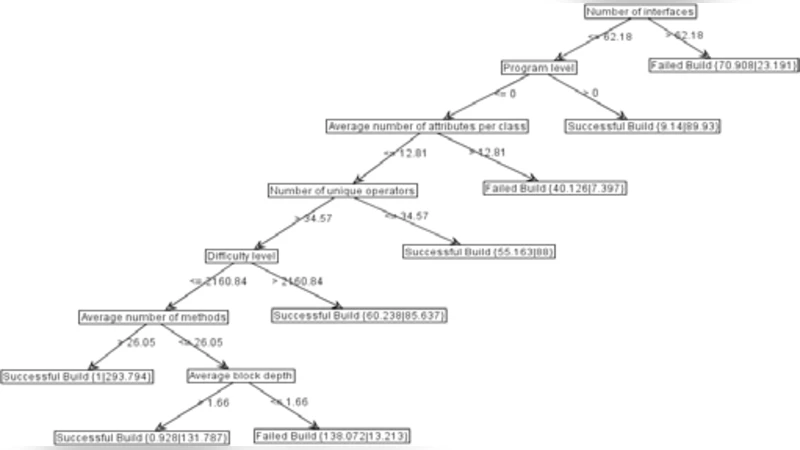
이 연구는 소프트웨어 개발 과정에서 발생하는 빌드 결과를 실시간으로 예측하기 위해 데이터 스트림 접근법을 채택하였다. 기존의 정적 데이터셋 기반 학습과 달리, 빌드가 진행될 때마다 새로운 인스턴스를 스트림에 추가함으로써 모델이 시간에 따라 진화하도록 설계하였다. 그러나 사용된 저장소의 빌드 기록이 제한적이었기 때문에 클래스 불균형 문제가 심각했다. 특히 실패 빌드가 전체의 10% 미만에 불과해 기존 학습 알고리즘은 다수 클래스에 편향되는 경향을 보였다. 이를 해결하기 위해 SMOTE(Synthetic Minority Over-sampling Technique)를 적용해 소수 클래스인 실패 빌드 데이터를 인공적으로 증식하였다. SMOTE는 기존 소수 클래스 샘플의 특성을 기반으로 새로운 합성 샘플을 생성함으로써 결정 경계 주변의 데이터 밀도를 높이고, 분류기의 일반화 능력을 향상시킨다.
모델링 단계에서는 Hoeffding Tree와 같은 스트림 의사결정트리를 사용했으며, 이는 제한된 메모리와 한 번의 패스 학습을 가능하게 한다. 실험 결과, 전체 1,200여 건의 빌드 인스턴스 중 약 900건이 모델에 충분히 노출된 시점부터 정확도가 꾸준히 상승했으며, 최종적으로 80%에 근접하는 정확도를 기록하였다. 중요한 메트릭으로는 코드 복잡도, 변경 라인 수, 파일 수 등이 도출되었으며, 이들 소수 몇 개만으로도 예측 성능을 크게 끌어올릴 수 있었다. 다만, 데이터 스트림 동안 클래스 비율이 변동하면서 일시적인 편향이 발생했으며, 이는 SMOTE 적용 후에도 완전히 해소되지 않았다. 따라서 향후 연구에서는 동적 클래스 비율 추정 및 적응형 오버샘플링 전략을 도입해 편향을 최소화하는 방안을 모색할 필요가 있다.
이 논문은 제한된 소스 코드 메트릭 데이터에 대해 스트림 기반 학습과 SMOTE를 결합함으로써 실시간 빌드 결과 예측 가능성을 입증했으며, 소프트웨어 품질 관리와 지속적 통합 파이프라인에 적용할 수 있는 실용적인 방법론을 제시한다.