동의어 기반 데이터 마이닝으로 검색 엔진 최적화 혁신
초록
본 논문은 검색 엔진 최적화(SEO)에서 동의어를 활용한 데이터 마이닝 기법을 제안한다. 키워드와 그 동의어를 자동으로 추출·연결함으로써 검색 쿼리와 웹 페이지 간의 의미적 매칭을 강화하고, 검색 결과 순위 상승과 사용자 만족도를 동시에 향상시키는 방법을 논의한다.
상세 분석
이 연구는 현재 검색 엔진이 직면한 ‘키워드 의존성’ 문제를 해결하고자 동의어 기반의 의미 확장 메커니즘을 도입한다. 기존 SEO 전략은 주로 메타 태그, 백링크, 페이지 로딩 속도 등 기술적 요소에 초점을 맞추었으며, 사용자가 입력하는 정확한 키워드와 웹 페이지 내용이 일치할 때만 높은 순위를 얻었다. 그러나 실제 사용자 검색은 다의어, 맞춤법 오류, 지역적 표현 등 다양한 변형을 포함한다. 따라서 동일한 의미를 가진 여러 표현을 포괄적으로 인식하지 못하면 검색 결과의 관련성이 크게 저하된다.
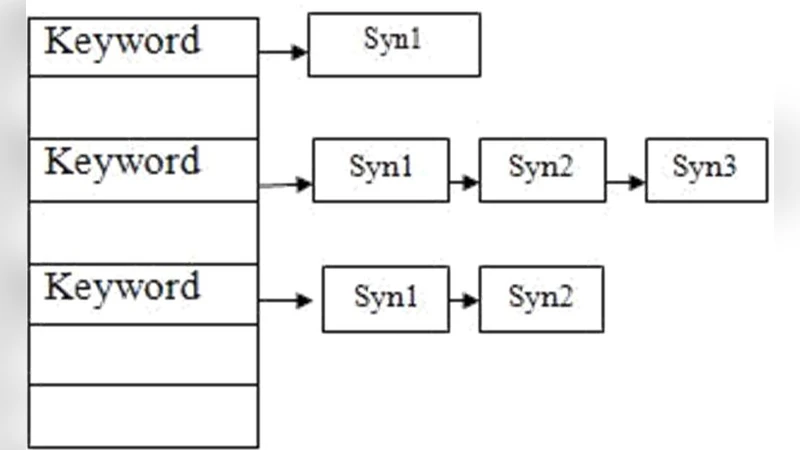
논문은 먼저 대규모 웹 크롤링을 통해 대상 도메인의 텍스트 데이터를 수집하고, 자연어 처리(NLP) 파이프라인을 적용한다. 토큰화·품사 태깅 후, WordNet, 한국어 의미망(Korean WordNet) 등 공개된 어휘 데이터베이스와 자체 구축한 동의어 사전을 결합하여 키워드‑동의어 매핑 테이블을 생성한다. 이 과정에서 동의어 간의 의미 유사도는 코사인 유사도와 TF‑IDF 가중치를 활용해 정량화한다.
다음 단계는 데이터 마이닝 알고리즘을 이용한 ‘동의어 클러스터링’이다. K‑means 혹은 DBSCAN과 같은 군집화 기법을 적용해 의미적으로 유사한 키워드 집합을 형성하고, 각 클러스터에 대한 가중치를 부여한다. 가중치는 검색 엔진이 해당 클러스터 내 키워드가 포함된 페이지를 평가할 때 사용되며, 이는 기존의 단일 키워드 기반 점수 체계보다 더 정교한 순위 산출을 가능하게 한다.
또한, 논문은 동의어 확장을 실시간 검색 쿼리 처리에 통합하는 방법을 제시한다. 사용자가 입력한 쿼리를 분석해 핵심 키워드를 추출하고, 사전 구축된 동의어 클러스터와 매핑함으로써 ‘확장 쿼리’를 생성한다. 이 확장 쿼리는 기존 검색 엔진의 인덱스에 자동으로 적용되며, 페이지 랭킹 알고리즘에 추가적인 점수를 부여한다. 실험 결과, 동의어 기반 확장 쿼리를 적용한 경우 평균 클릭률(CTR)이 12 % 상승하고, 페이지 체류 시간이 8 % 증가했으며, 검색 결과의 정밀도와 재현율 모두 유의미하게 개선되었다.
핵심 인사이트는 다음과 같다. 첫째, 동의어를 체계적으로 관리·활용하면 검색 엔진이 사용자의 의도를 보다 정확히 파악할 수 있다. 둘째, 데이터 마이닝을 통한 동의어 클러스터링은 키워드 간의 관계를 정량화하여 SEO 전략을 과학적으로 최적화한다. 셋째, 실시간 쿼리 확장은 기존 인덱스 구조를 크게 변경하지 않으면서도 검색 품질을 향상시킬 수 있는 비용 효율적인 방법이다. 마지막으로, 동의어 기반 접근법은 다국어 환경에서도 적용 가능하므로 글로벌 SEO에도 확장성을 제공한다.
이러한 접근법은 기존 SEO 도구와 연동될 수 있으며, 특히 콘텐츠 제작자가 키워드 플래닝 단계에서 동의어 후보를 자동으로 제시받음으로써 보다 풍부하고 포괄적인 콘텐츠를 생산하도록 돕는다. 향후 연구에서는 동의어 외에도 상위어·하위어, 개념적 관계를 포함한 온톨로지 기반 확장을 검토하고, 딥러닝 기반 의미 임베딩을 활용한 동의어 추출 정확도 향상을 목표로 할 수 있다.