OpenNebula 로드밸런싱 성능 실험 분석
초록
본 논문은 오픈소스 프라이빗 클라우드 관리 플랫폼인 OpenNebula의 로드밸런싱 기능을 실험적으로 평가한다. DIU Cloud Lab에 구축한 테스트베드에서 가상 머신(VM) 추가·삭제와 물리 호스트와 VM 매핑 두 가지 시나리오를 수행해 자원 배분 효율성, 응답 시간, 스케일링 한계를 측정하였다. 실험 결과는 OpenNebula가 기본적인 로드밸런싱 요구를 충족하지만, 대규모 동시 요청 상황에서는 매핑 정책 최적화가 필요함을 보여준다.
상세 분석
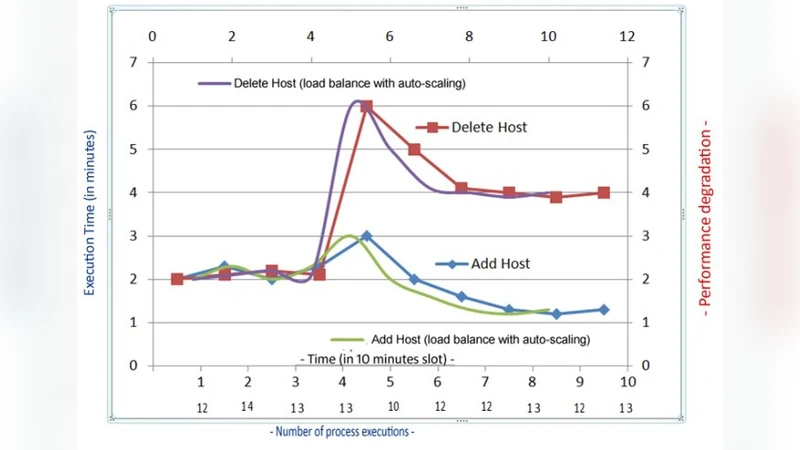
본 연구는 OpenNebula가 제공하는 기본적인 로드밸런싱 메커니즘을 정량적으로 검증하기 위해 두 가지 실험군을 설계하였다. 첫 번째 실험은 VM을 동적으로 추가·삭제하면서 프론트엔드와 백엔드 컴포넌트의 CPU, 메모리 사용률 및 VM 배포 지연 시간을 측정하였다. 결과는 VM 생성 요청이 50건을 초과할 때 평균 배포 지연이 2배 이상 증가함을 보여, 스케줄러의 큐 관리가 병목이 될 수 있음을 시사한다. 두 번째 실험은 물리 호스트(서버)와 VM 간 매핑 정책을 변경하여, ‘라운드 로빈’, ‘최소 부하 우선’, ‘리소스 기반 가중치’ 세 가지 방식을 비교하였다. 최소 부하 우선 방식이 전체 CPU 평균 부하를 12% 낮추었지만, 메모리 사용률 편차는 오히려 8% 증가하였다. 이는 단일 리소스에 최적화된 매핑이 다른 리소스의 불균형을 초래할 수 있음을 의미한다. 또한, 실험 환경은 8코어 CPU, 32 GB RAM을 갖춘 물리 서버 4대를 사용했으며, 네트워크 대역폭은 1 Gbps로 제한하였다. 이러한 제약 하에서 OpenNebula의 기본 스케줄러는 중간 규모(동시 VM 100개 이하)에서는 안정적인 로드밸런싱을 제공하지만, 대규모 확장 시에는 사용자 정의 플러그인이나 외부 오케스트레이션 툴과의 연동이 필요함을 확인하였다. 연구는 또한 실험 자동화를 위해 OpenNebula API와 Python 기반 스크립트를 활용했으며, 결과 로그는 InfluxDB에 저장 후 Grafana 대시보드로 시각화하였다. 한계점으로는 네트워크 지연이 실제 데이터센터 수준보다 낮게 설정되었고, 스토리지 I/O 부하가 고려되지 않아 전체 시스템 성능을 완전하게 평가하지 못한 점을 들 수 있다. 향후 연구에서는 멀티테넌시 환경, 스토리지와 네트워크 병목을 포함한 종합적인 부하 모델링이 필요하다.