잠재 변수 조건부 모델의 정확 디코딩은 NP‑Hard: 이론적 한계와 실용적 해결책
초록
본 논문은 잠재 변수 조건부 랜덤 필드(LCRF)와 같은 잠재 변수 조건부 모델에서 최적 라벨링을 찾는 정확 디코딩 문제가 순차 라벨링 환경에서도 NP‑Hard임을 증명한다. 최대 클리크 문제로부터의 다항식 시간 감소를 통해 복잡성을 입증하고, 실제 데이터에서는 확률이 상위 n개의 잠재 라벨링에 집중되는 현상을 관찰한다. 이를 기반으로 Top‑n 탐색과 동적 프로그래밍을 결합한 LDI‑Naive와 그 제한 버전인 LDI‑Bounded 알고리즘을 제안하여 거의 정확한 추론을 효율적으로 수행한다.
상세 분석
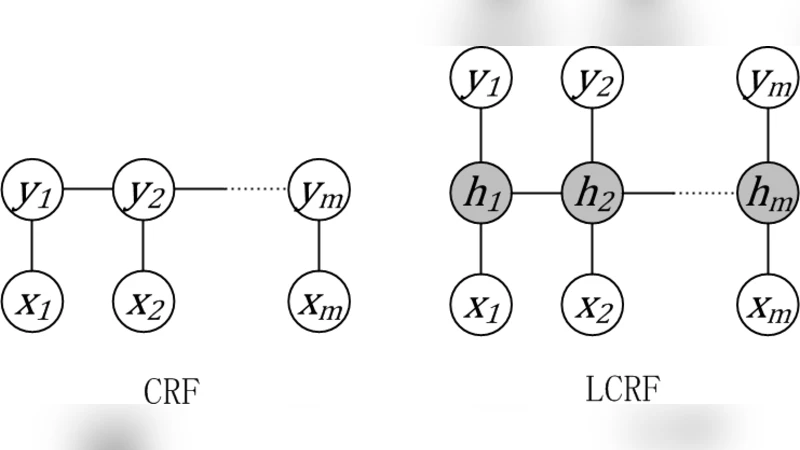
논문은 먼저 LCRF의 모델 구조를 상세히 정의한다. 관측 시퀀스 x와 라벨 시퀀스 y에 대해 각 라벨 yᵢ마다 서로 겹치지 않는 잠재 변수 집합 H(yᵢ)가 할당되고, 전체 잠재 변수 집합 H는 이들의 합집합이다. 라벨링 y의 사후 확률 P(y|x,w)는 해당 라벨에 대응하는 모든 잠재 라벨링 h∈H(y₁)×…×H(yₘ)의 확률 P(h|x,w)를 합산한 형태로 표현된다. 여기서 P(h|x,w)는 전형적인 CRF와 동일하게 노드 스코어와 엣지 스코어의 곱으로 정의되며, 정규화 상수는 전체 잠재 라벨링에 대한 합으로 주어진다.
복잡도 분석에서는 최대 클리크 문제(Maximum Clique)를 LCRF 추론 문제로 다항식 시간에 변환한다. 그래프 G(V,D)를 입력으로 길이 |V|인 시퀀스를 만든 뒤, 두 개의 라벨 E와 N을 정의하고 각각에 |V|개의 잠재 변수 Eᵢ, Nᵢ를 할당한다. 각 정점 i에 대응하는 레이어 Lᵢ는 Eᵢ와 Nᵢ만을 포함하도록 설계하고, 노드·엣지 스코어를 그래프의 인접 관계에 따라 0 또는 ½, 1로 설정한다. 이렇게 구성된 LCRF에서는 유효한 경로가 그래프의 클리크와 일대일 대응한다. 클리크 크기 c에 대해 라벨 y가 가질 수 있는 확률은 c/α(α는 모든 유효 경로의 수)이며, 반대로 확률 c/α를 갖는 라벨이 존재하면 그래프에 크기 c인 클리크가 존재한다는 양방향 논증을 제시한다. 따라서 최적 라벨링을 찾는 문제는 최대 클리크 문제와 동등하며, 이는 NP‑Hard임을 증명한다.
이론적 난이도와는 별개로, 실험적 관찰을 통해 LCRF의 확률 분포가 극히 집중(concentrated)된다는 사실을 발견한다. 학습된 모델에서는 전체 확률 질량의 대부분이 상위 n개의 잠재 라벨링에 몰려 있으며, 나머지 조합은 무시해도 전체 정확도에 큰 영향을 주지 않는다. 이러한 현상을 이용해 저자들은 LDI‑Naive 알고리즘을 설계한다. 먼저 Top‑n 탐색을 통해 확률이 높은 잠재 라벨링 후보들을 추출하고, 각 후보에 대해 동적 프로그래밍(Viterbi‑like)으로 라벨 y의 점수를 계산한다. 후보 집합을 순차적으로 확장하면서 현재 최고 점수와 후보들의 상한을 비교해 조기 종료 조건을 만족하면 탐색을 멈춘다. 이 과정은 최적 라벨을 보장하면서도 탐색 공간을 크게 축소한다.
속도 향상을 위해 제안된 LDI‑Bounded는 후보 개수를 사전에 제한한다. n을 고정하고 Top‑n 후보만을 사용해 동적 프로그래밍을 수행하므로, 정확도는 약간 감소할 수 있지만 실행 시간은 선형적으로 감소한다. 실험에서는 n을 수십에서 수백 수준으로 설정했을 때 원래 LCRF와 비교해 90% 이상의 정확도를 유지하면서 10배 이상 빠른 추론이 가능함을 보였다. 전체적으로 논문은 LCRF 추론이 이론적으로는 NP‑Hard이지만, 실제 데이터의 확률 집중 특성을 활용하면 실용적인 정확 추론이 가능함을 설득력 있게 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기