대규모 그래프 요약을 위한 어휘 기반 압축 방법
초록
본 논문은 대규모 그래프를 몇 가지 대표적인 서브그래프(별, 클리크, 체인, 이분 그래프 등)로 요약하고, 최소 설명 길이(MDL) 원리를 이용해 가장 정보량이 큰 구조들을 자동으로 선택하는 VoG라는 프레임워크를 제안한다. 후보 서브그래프를 생성·분류한 뒤, 중복을 최소화하면서 전체 설명 길이를 최소화하는 모델을 탐색한다. 실험에서는 수백만 개의 엣지를 가진 실제 네트워크에서 의미 있는 패턴을 성공적으로 발견한다.
상세 분석
VoG는 그래프 요약을 “정보 압축” 문제로 정형화한다는 점에서 혁신적이다. 저자들은 먼저 실제 네트워크에서 자주 나타나는 6가지 기본 구조(완전·근접 클리크, 완전·근접 이분 코어, 별, 체인)를 어휘(vocabulary)로 정의하고, 각 구조를 하나의 모델 요소로 본다. 모델 M은 이러한 요소들의 순서가 있는 리스트이며, 각 요소는 그래프의 인접 행렬에서 특정 영역을 차지한다. MDL 원리에 따라 전체 설명 길이 L(G,M)=L(M)+L(E) 를 최소화하는 M을 찾는다. 여기서 L(M)은 모델 자체를 기술하는 비트 수, L(E)는 모델이 설명하지 못한 오류 행렬을 코딩하는 비트 수이다.
각 구조 타입별 코딩 방식이 상세히 설계되었다. 예를 들어 완전 클리크는 노드 수와 노드 ID만 전송하면 되지만, 근접 클리크는 존재·부존재 엣지를 각각 최적 프리픽스 코드로 압축한다. 이분 코어와 별도 유사한 방식으로 처리되며, 체인은 순서가 중요한 특성을 반영해 노드 순서를 인코딩한다. 오류 행렬은 과잉 엣지(E⁺)와 누락 엣지(E⁻)로 나누어 각각 별도 프리픽스 코딩한다. 이러한 정교한 코딩 스킴은 구조가 실제 그래프에 얼마나 잘 맞는지를 정량적으로 평가할 수 있게 해준다.
검색 공간은 모든 가능한 서브그래프 조합으로 사실상 NP‑hard 수준이지만, 저자들은 실용적인 휴리스틱을 도입한다. 먼저 다양한 그래프 분해 기법(예: 메타클러스터링, 트리 분해)으로 후보 서브그래프를 생성하고, 각 후보를 MDL 기준으로 가장 적합한 어휘 타입에 라벨링한다. 이후 “Plain”, “Top10”, “Top100”, “Greedy’NForget” 등 네 가지 선택 전략을 적용해 중복을 최소화하면서 설명 길이 감소 효과가 큰 구조를 순차적으로 추가한다. 특히 Greedy’NForget은 현재 모델에 가장 큰 압축 이득을 주는 후보를 선택하고, 선택 후에는 중복되는 영역을 재평가해 제거하는 반복 과정을 수행한다.
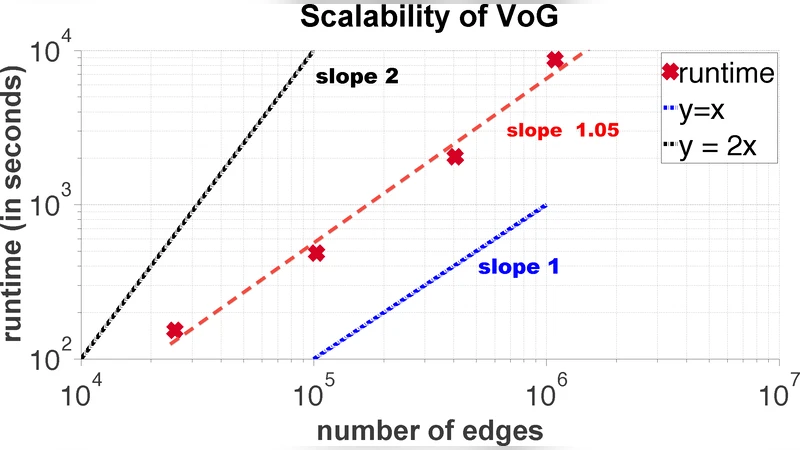
실험에서는 Flickr, Notre Dame 웹 그래프, 위키피디아 논쟁 그래프 등 10여 개의 대규모 실데이터에 대해 VoG를 적용했다. 결과는 압축 비율(원본 대비 비트 수 감소)과 발견된 구조의 의미적 해석 두 측면에서 기존 커뮤니티 탐지·그래프 분해 기법보다 우수함을 보여준다. 예를 들어 위키피디아 논쟁 그래프에서는 별 구조가 핵심 편집자를, 근접 이분 코어가 ‘편집 전쟁’ 양측을 명확히 드러냈다. 또한, 알고리즘의 실행 시간은 엣지 수에 거의 선형에 가깝게 증가해 실용적인 규모에서도 적용 가능함을 입증한다.
한계점으로는 어휘가 고정되어 있어 도메인 특화 구조(예: 트리, 모듈러 그래프 등)를 포착하기 어려울 수 있다는 점, 그리고 후보 생성 단계가 입력 그래프의 특성에 따라 품질이 크게 좌우된다는 점을 들 수 있다. 향후 연구에서는 어휘 자동 확장, 동적 후보 생성, 그리고 지도 학습 기반 구조 선택 등을 통해 이러한 제약을 완화할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기