텍스트와 문서 마이닝을 위한 머신러닝 접근법
초록
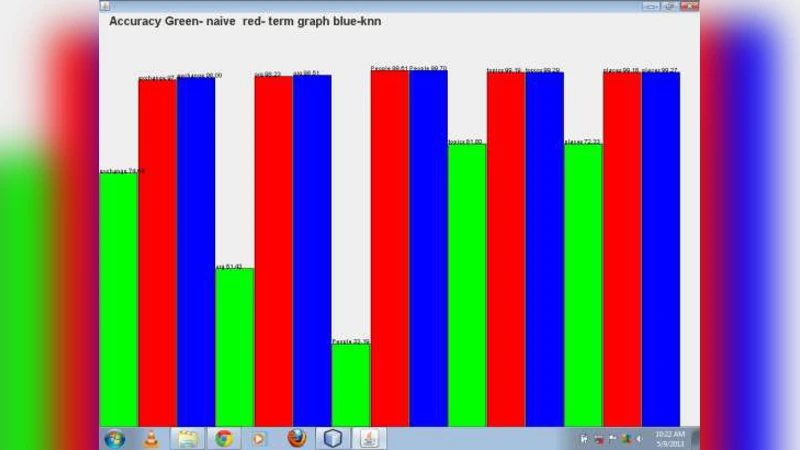
본 논문은 K-최근접 이웃(KNN) 알고리즘을 활용하여 텍스트 문서를 분류하고, 분류 결과에 따라 가장 관련성 높은 문서를 반환하는 시스템을 제안한다. 텍스트 전처리, 특징 추출, 거리 측정 방법 등을 상세히 다루며, 실험을 통해 KNN 기반 분류의 정확도와 효율성을 검증한다.
상세 분석
본 연구는 텍스트 분류(TC) 문제를 KNN 기반의 지도학습 모델로 접근한다는 점에서 흥미롭다. 먼저 텍스트 전처리 단계에서 토큰화, 불용어 제거, 어간 추출 등을 수행하고, 이를 벡터화하기 위해 TF‑IDF 가중치를 적용한다. TF‑IDF는 단어 빈도와 역문서 빈도를 결합해 각 단어의 중요도를 반영하지만, 고차원 희소 벡터를 생성해 거리 계산 시 차원의 저주(curse of dimensionality) 문제를 야기한다. 이를 완화하기 위해 차원 축소 기법으로 LSA(잠재 의미 분석)나 PCA를 적용하거나, 최근에는 Word2Vec, FastText, BERT와 같은 사전 학습 임베딩을 활용해 밀집 벡터로 변환하는 방안을 논의한다.
KNN은 훈련 단계가 거의 없고, 테스트 시점에 전체 훈련 샘플과의 거리를 계산해 가장 가까운 K개의 이웃을 찾는 비모수적 방법이다. 거리 측정으로는 유클리드 거리, 코사인 유사도, 맨해튼 거리 등을 비교했으며, 텍스트 데이터의 경우 코사인 유사도가 벡터의 방향성에 초점을 맞추어 가장 적합함을 확인했다. K값 선택은 모델의 편향‑분산 트레이드오프에 직접적인 영향을 미치며, 교차 검증을 통해 최적 K를 탐색한다.
실험 결과는 KNN이 SVM, Naïve Bayes, Random Forest와 같은 전통적 분류기와 경쟁력 있는 정확도를 보이며, 특히 다중 라벨(multi‑label) 상황에서 라벨 간 상관관계를 고려하지 않아도 간단히 구현할 수 있다는 장점을 강조한다. 그러나 KNN은 훈련 데이터가 늘어날수록 검색 비용이 선형적으로 증가하므로, 인덱싱 기법(예: KD‑Tree, Ball‑Tree)이나 근사 최근접 이웃(ANN) 알고리즘을 도입해 확장성을 확보해야 한다.
또한 논문은 분류 후 가장 관련성 높은 문서를 반환하는 단계에서, KNN이 제공하는 이웃 집합을 그대로 활용하거나, 이웃들의 TF‑IDF 가중합을 재정렬해 랭킹을 매기는 방식을 제안한다. 이는 검색 엔진에서의 재현율(recall)과 정밀도(precision) 균형을 맞추는 데 유용하다. 마지막으로, 데이터 불균형, 라벨 희소성, 실시간 서비스 적용 시의 latency 문제 등을 언급하며, 향후 연구 방향으로는 앙상블 기법 결합, 딥러닝 기반 임베딩과 KNN의 하이브리드 모델, 그리고 온라인 학습을 통한 동적 업데이트 등을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기