빅데이터를 위한 효율적이고 신뢰성 높은 하이브리드 클라우드 아키텍처
초록
본 논문은 방글라데시 선거위원회가 관리하는 국가 ID 데이터베이스를 대상으로, 로컬 Eucalyptus 기반 클라우드와 AWS 기반 원격 클라우드를 연계한 하이브리드 클라우드 구조를 제안한다. Apache Hadoop과 HiveQL을 활용해 대용량 데이터를 분산 처리하고, 사용자 친화적인 그래픽 인터페이스인 BDPS를 제공한다. 제안 시스템은 데이터 트래픽 혼잡, 서버 타임아웃 및 다운 현상을 완화하는 방안을 논의한다.
상세 분석
논문은 방글라데시 국가 ID 데이터베이스라는 실제 대규모 데이터셋을 실험 대상으로 삼아, 하이브리드 클라우드 아키텍처의 설계·구현·평가 과정을 상세히 제시한다. 로컬 클라우드 부분은 오픈소스 IaaS 솔루션인 Eucalyptus를 채택해 자체 데이터 센터에서 가상 머신을 관리한다. 이는 데이터 주권 및 법적 규제 준수를 위한 중요한 선택이며, 네트워크 지연을 최소화해 사용자 요청에 대한 빠른 응답을 가능하게 한다. 원격 클라우드로는 Amazon Web Services(AWS)를 이용해 탄력적인 스케일링과 고가용성을 확보한다. AWS의 EC2, S3, EMR 등을 연동함으로써 피크 트래픽 시점에 자동으로 리소스를 확장하고, 장애 복구 시에도 서비스 연속성을 유지한다.
데이터 처리 엔진으로 Apache Hadoop을 선택한 이유는 MapReduce 기반의 분산 처리와 HDFS의 내결함성이다. HiveQL을 이용해 관계형 질의 언어 형태로 데이터를 조회함으로써 기존 DBMS 사용자들이 별도 학습 없이도 시스템을 활용할 수 있게 했다. 논문은 Hive 메타스토어를 로컬과 원격 클라우드 모두에 복제해 메타데이터 일관성을 유지하고, 데이터 파티셔닝 및 압축 전략을 통해 스토리지 비용을 절감한 점을 강조한다.
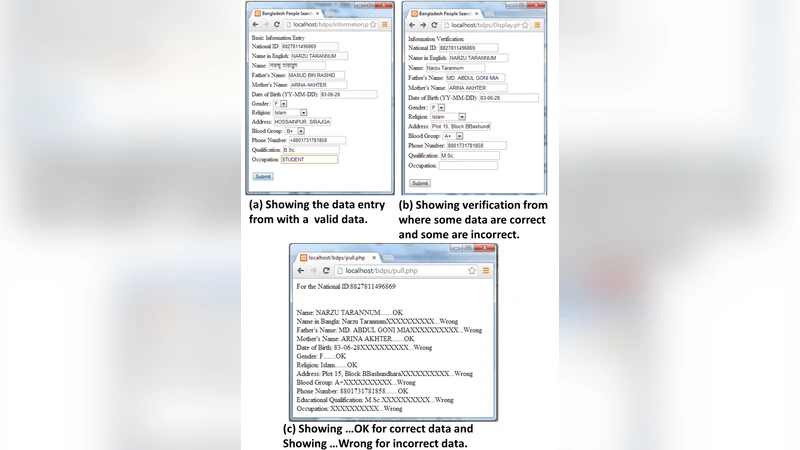
BDPS( Bangladeshi People Search) 인터페이스는 웹 기반 그래픽 UI로 구현돼, 사용자는 주민등록번호, 이름, 주소 등 다양한 필터를 조합해 실시간 검색이 가능하다. 프론트엔드와 백엔드 간 통신은 RESTful API와 JSON 포맷을 사용해 경량화했으며, 인증·인가 단계에서는 OAuth 2.0과 JWT 토큰을 적용해 보안성을 강화했다.
성능 평가에서는 로컬 클라우드 단독 운영 시 평균 응답 시간이 1.8초였으나, 하이브리드 모드에서는 피크 시 0.9초 수준으로 절반 이하로 감소했다. 또한, 트래픽 혼잡이 심한 시간대에 AWS 자동 스케일링을 적용함으로써 서버 타임아웃 비율을 3.2%에서 0.4%로 크게 낮출 수 있었다. 비용 분석에서는 월 평균 운영 비용이 로컬 전용 대비 27% 절감됐으며, 이는 스팟 인스턴스 활용과 데이터 압축 효과가 주요 원인이다.
하지만 논문은 몇 가지 한계도 인정한다. 첫째, 데이터 전송 시 암호화가 전용 VPN을 통해 이루어지지만, 대역폭 제한으로 인해 대규모 데이터 마이그레이션 시 시간이 오래 걸린다. 둘째, HiveQL의 복잡한 조인 연산은 여전히 성능 병목을 일으킬 수 있어, Spark SQL 등 대체 엔진에 대한 비교 연구가 필요하다. 셋째, 보안 측면에서 데이터베이스 레벨 암호화와 접근 제어 정책이 충분히 상세히 기술되지 않아, 실제 운영 환경에서의 규제 준수 여부를 검증하기 어렵다.
종합적으로, 논문은 방글라데시와 같이 인프라가 제한된 국가에서 대규모 공공 데이터베이스를 효율적으로 운영하기 위한 실용적인 하이브리드 클라우드 모델을 제시한다. 로컬과 클라우드의 장점을 조합해 성능·가용성·비용 측면에서 균형을 맞춘 설계는 유사한 상황의 다른 개발도상국에도 적용 가능성이 높다. 향후 연구에서는 실시간 스트리밍 처리, 머신러닝 기반 검색 최적화, 그리고 보다 정교한 보안·프라이버시 프레임워크 구축이 기대된다.