FPGA 기반 이미지 처리 설계 공간 탐색
초록
**
본 논문은 이미지·비디오 처리, 통신·암호화 등 임베디드 응용 분야에서 FPGA가 제공하는 높은 병렬성, 재구성 가능성 및 DSP 자원을 활용한 설계 방법론을 종합적으로 검토한다. 소프트웨어 알고리즘을 하드웨어로 변환하는 과정, 최적화 기법, 설계 흐름, 기존 연구와의 비교를 통해 FPGA가 실시간 고성능 이미지 처리에 적합한 플랫폼임을 입증한다.
**
상세 분석
**
이 논문은 FPGA가 이미지 처리 가속기에 적합한 이유를 세 가지 관점에서 심층적으로 분석한다. 첫째, 하드웨어 병렬성이다. 이미지 필터링, 컨볼루션, 히스토그램 등 저수준 연산은 픽셀 단위의 독립적인 연산이 다수 존재하므로, FPGA 내부의 CLB, DSP 슬라이스, BRAM을 활용해 각 연산을 완전 병렬화할 수 있다. 논문은 루프 언롤링, 루프 퓨전, 파이프라인 삽입 등 고전적인 HLS 최적화 기법이 자원 활용률을 30 % 이상 향상시키고, 처리량을 수십 배까지 끌어올릴 수 있음을 실험 결과와 함께 제시한다.
둘째, 재구성 가능성이다. 설계 단계에서 하드웨어 구조를 반복적으로 수정할 수 있는 FPGA‑in‑the‑Loop(FIL) 검증 흐름을 제시한다. 설계자는 알고리즘 수준에서 파라미터(예: 필터 커널 크기, 고정소수점 비트폭)를 조정하고, 즉시 하드웨어 시뮬레이션을 통해 성능·전력·자원 사용량을 피드백받는다. 이는 ASIC 설계와 달리 비싼 마스크 비용 없이 설계 반복을 가능하게 하며, 특히 저볼륨·맞춤형 제품에 큰 장점을 제공한다.
셋째, 비용·전력 효율이다. 논문은 FPGA가 ASIC 대비 초기 NRE 비용이 낮고, 저볼륨 생산에서도 경제적임을 강조한다. 또한, FPGA 내부에 존재하는 DSP 블록을 활용하면 고정소수점 연산을 효율적으로 수행할 수 있어 전력 소모를 최소화한다. 다만, FPGA는 일반적으로 ASIC보다 클럭 주파수가 낮고, 복잡한 부동소수점 연산은 자원과 전력을 많이 소모한다는 한계도 명시한다. 이러한 한계를 극복하기 위해 설계자는 연산을 고정소수점으로 변환하거나, 멀티플라이어‑리스 컨볼루션(MC) 같은 특수 구조를 적용한다.
논문은 또한 기존 연구들을 체계적으로 정리한다. LUT‑기반, 분산 산술(DA), 멀티플라이어‑리스 컨볼루션, 이동 윈도우 메모리 구조 등 다양한 아키텍처를 비교하면서, 각 방법이 메모리 대역폭, 파이프라인 깊이, 자원 사용량에 미치는 영향을 상세히 분석한다. 특히, 2‑D 이동 윈도우와 부분 버퍼링 기법이 외부 메모리 접근을 최소화하고, 고해상도 영상 처리에서 병목을 크게 완화한다는 점을 강조한다.
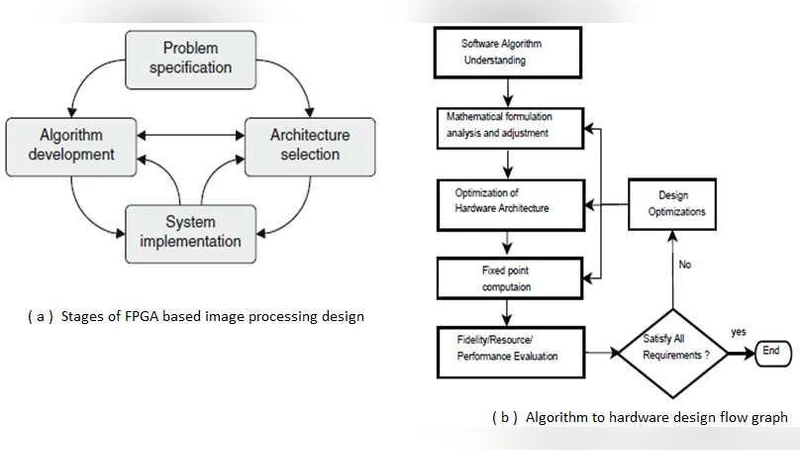
마지막으로, 설계 흐름을 알고리즘‑하드웨어 변환 단계(Algorithm‑to‑Hardware Flow)로 정리한다. 1) 알고리즘 이해 및 소프트웨어 구현, 2) 알고리즘 수준 최적화(대수 변환, 고정소수점 양자화), 3) 하드웨어 수준 최적화(스토리지 구조, 파이프라인 설계), 4) FPGA‑in‑the‑Loop 검증, 5) 성능·자원·전력 평가 및 반복 설계. 이 흐름은 설계자가 체계적으로 설계 공간을 탐색하고, 목표 응용에 최적화된 아키텍처를 도출하도록 돕는다.
요약하면, 논문은 FPGA가 제공하는 고성능 병렬 처리, 유연한 재구성, 비용·전력 효율을 기반으로 이미지 처리 시스템 설계에 적용할 수 있는 구체적인 방법론과 설계 공간 탐색 기법을 제시하며, 향후 SoC‑레벨 통합 및 자동화된 HLS 툴 체인 개발 방향을 제언한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기