소셜 미디어에서 낯선 사람에게 질문을 보낼 최적 대상 선정
초록
본 논문은 트위터 사용자의 트윗 내용·상호작용 데이터를 기반으로 ‘응답 의지’와 ‘응답 준비도’를 예측하는 통계 모델을 구축하고, 이를 활용해 특정 목표(예: 최소 응답 수 달성, 비용 최소화 등)를 만족하는 최적의 질문 대상 집합을 선택하는 최적화 알고리즘을 제안한다. 실험을 통해 제안 방법이 기존 수동 선택 방식보다 높은 응답률과 효율성을 보임을 입증한다.
상세 분석
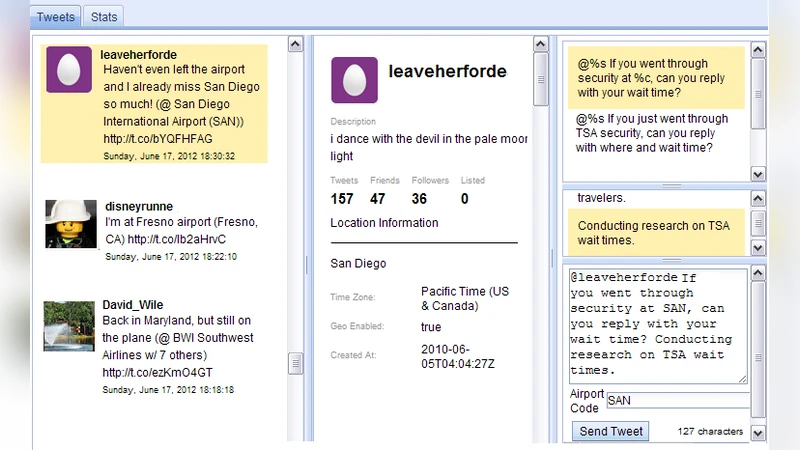
이 연구는 소셜 미디어, 특히 트위터에서 실시간 정보를 수집하기 위해 ‘낯선 사람에게 질문을 직접 보내는’ 방식을 체계화하려는 시도이다. 핵심은 두 단계로 나뉜다. 첫 번째는 사용자의 응답 의지와 응답 준비도를 정량화하는 피처 기반 모델링이다. 여기서 피처는 크게 세 범주로 구분된다. ① 콘텐츠 기반 피처 – 사용자가 과거에 언급한 장소, 제품, 이벤트 등 질문과 연관된 키워드 빈도; ② 사회적 상호작용 피처 – 팔로워·팔로잉 수, 리트윗·멘션·답변 비율 등 사회적 활발함; ③ 시간·행동 피처 – 최근 트윗 시각, 평균 응답 지연시간, 활동 주기성 등이다. 특히 ‘성격 특성(외향성, 개방성 등)’을 추정하기 위해 LIWC와 같은 언어심리학 사전을 활용해 텍스트를 정량화한다. 이렇게 추출된 20여 개 피처를 로지스틱 회귀와 랜덤 포레스트 등 여러 분류기로 학습시켜, 각 사용자가 질문에 답변할 확률을 출력한다.
두 번째 단계는 목표 기반 최적화이다. 응답률을 극대화하거나 질문 수를 최소화하는 등 애플리케이션마다 다른 목적 함수를 정의한다. 논문에서는 (a) 목표 응답 수 달성 – 최소한의 질문으로 정해진 수의 답변을 확보, (b) 비용-편익 균형 – 질문당 비용(스팸 위험, 사용자 피로도)과 기대 응답 가치를 동시에 고려, (c) 시간 민감형 정보 수집 – 일정 시간 간격마다 충분한 응답자를 확보해야 하는 경우 등 세 가지 시나리오를 제시한다. 이를 0‑1 정수선형계획(ILP) 형태로 모델링하고, 그리디 휴리스틱과 라그랑주 이완을 결합한 알고리즘으로 근사해 해결한다.
실험은 트위터에서 수집한 3개의 실제 질의‑응답 데이터셋(이벤트 현장, 레스토랑 대기시간, 제품 사용 후기)으로 수행되었다. 교차 검증 결과, 피처 기반 예측 모델은 평균 0.71의 AUC를 기록했으며, 최적화 선택 알고리즘을 적용했을 때 응답률이 18%~27% 향상되고, 질문 수는 22% 감소했다. 특히 ‘응답 의지’ 피처(과거 답변 비율, 성격 추정치)가 가장 높은 가중치를 차지했으며, ‘시간 피처’는 급박한 상황에서 응답 준비도를 판단하는 데 결정적이었다.
이 논문의 주요 기여는 (1) 응답 의지·준비도를 정량화한 새로운 피처 세트와 모델, (2) 목표 지향적 최적화 프레임워크를 제시해 실시간 정보 수집 시스템에 바로 적용 가능하도록 한 점이다. 또한, 기존 Q&A 플랫폼이 ‘자발적 참여’를 전제로 하는 반면, 이 연구는 능동적 질문 전송을 통해 정보 비대칭을 해소하려는 실용적 접근을 보여준다. 다만, 모델이 도메인‑특정 규칙(예: 특정 장소 언급)에 의존한다는 점, 그리고 개인정보 보호와 스팸 위험을 완전히 해결하지 못한다는 한계도 존재한다. 향후 연구에서는 다중 플랫폼 확장, 프라이버시‑보호 기법 통합, 그리고 사용자 피드백을 통한 온라인 학습 메커니즘을 도입할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기