펜타고 완전 해결: 병렬 인코어 레트로그레이드 분석으로 1인 승리 입증
초록
본 논문은 6×6 보드와 4개의 3×3 사분면으로 구성된 퍼즐 게임 펜타고를 완전 강력 해결(strongly solved)했음을 보고한다. 저자들은 98304개의 스레드를 활용한 NERSC Cray Edison 슈퍼컴퓨터에서 4시간 만에 3 × 10¹⁵개의 상태를 전부 탐색했으며, 결과적으로 첫 번째 플레이어가 최적 플레이 시 반드시 승리한다는 것을 증명하였다. 핵심 기술은 대규모 메모리 내(in‑core) 레트로그레이드 분석, 대칭군을 이용한 상태 감소, 그리고 비동기식 메시지 전달을 통한 메모리 효율적 분산이다.
상세 분석
이 연구는 기존에 ‘수렴형(divergent)’ 게임이라 불리던 분야에서 최초로 레트로그레이드 방식만으로 완전 해결을 달성한 사례이다. 펜타고는 매 턴마다 돌을 놓고 사분면을 90도 회전시키는 복합 행동 때문에 평균 분기 계수가 97에 달한다. 저자들은 회전 추상화(rotation‑abstracted) 기법을 도입해 각 보드에 대해 256가지 회전 변형을 동시에 처리함으로써 회전으로 인한 8배의 분기 폭을 제거하고, 실제 평균 분기 계수를 12 수준으로 낮췄다.
대칭 처리에서는 전역 8원소 디헤드럴 군(D₄)뿐 아니라 각 사분면의 독립 회전군 Z₄⁴을 결합한 반직접곱 G = Z₄⁴ ⋊ D₄(2048원소)를 정의했다. 이 그룹을 이용해 ‘대표 보드’를 하나씩 선택하고, 각 대표 보드에 대해 L → {−1,0,1} 함수(256비트 테이블)를 저장함으로써 상태 공간을 15 % 정도만 중복한다. 데이터 레이아웃은 4차원 섹션(각 차원은 사분면의 돌 배치)으로 구성하고, 이를 8×8×8×8 블록으로 세분화해 프로세스 간 균등 분배를 구현했다.
병렬 구현에서는 두 인접 스톤 슬라이스(예: n‑stone, n+1‑stone)를 동시에 메모리에 유지해야 하는데, 전체 피크 메모리 요구량이 압축 전 213 TB에 달한다. 이를 감당하기 위해 저자들은 ‘즉시 요청-즉시 전송’ 비동기 메시징 모델을 채택했다. 프로세스가 필요로 하는 블록을 소유 프로세스에 요청하면, 소유자는 즉시 데이터를 반환하고, 요청자는 이를 받아 연산에 바로 투입한다. 이렇게 하면 통신 대기시간을 연산과 겹쳐 숨길 수 있었으며, 전체 실행 시간은 4시간 내외로 제한되었다.
또한, 블록 라인 단위의 작업을 무작위로 섞어 각 프로세스에 할당하는 ‘확정적 의사난수 파티셔닝’ 방식을 도입해 메모리와 연산 부하를 균등하게 분산시켰다. 이 방법은 복잡한 그래프 파티셔닝 없이도 중앙극한정리에 의해 자연스럽게 부하 균형을 달성한다.
성능 측면에서 펜타고는 3 × 10¹⁵ 상태(대칭 제거 후)로, 이전에 레트로그레이드로 해결된 가장 큰 게임인 체커(3.9 × 10¹³)보다 77배, 그리고 가장 큰 ‘비수렴형’ 게임인 9×6 Connect‑Four(2 × 10¹³)보다 150배 큰 규모다. 그러나 최종 데이터베이스는 3.7 TB(압축 후)로, 체커 엔드게임 테이블(140 TB)보다 훨씬 작다.
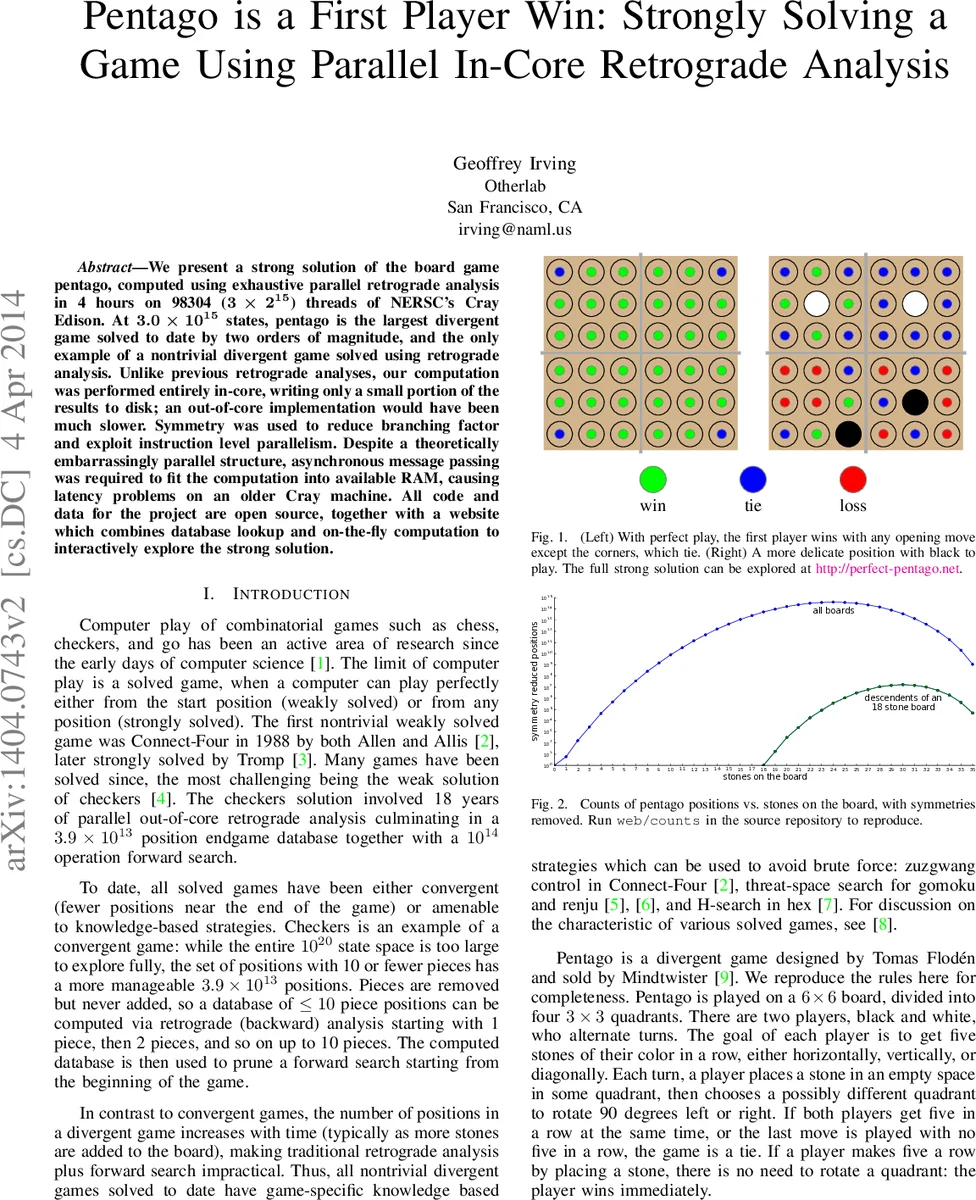
결과적으로, 첫 번째 플레이어는 모든 가능한 오프닝(코너 제외)에서 승리 경로를 확보하며, 코너 오프닝만이 무승부를 만든다. 저자들은 이 강력 해결 데이터를 웹 인터페이스와 API 형태로 공개했으며, 사용자는 실시간으로 최적 수를 조회하거나 직접 탐색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기