이름 패션의 확산: 내구재 시장 모델을 통한 예측
초록
본 연구는 마케팅 경제학에서 사용되는 Bass 확산 모델을 이름 선택에 적용하여, 프랑스·네덜란드·미국의 출생명 데이터에 로지스틱 모델을 적합시켰다. 이름의 유행을 ‘패션’으로 정의하고, 혁신(p) 없이 모방(q)만으로 전파되는 과정을 수학적으로 설명한다. 수천 개의 이름이 높은 적합도를 보였으며, 인기와 무관하게 작은 규모에서도 패션 현상이 나타남을 확인했다.
상세 분석
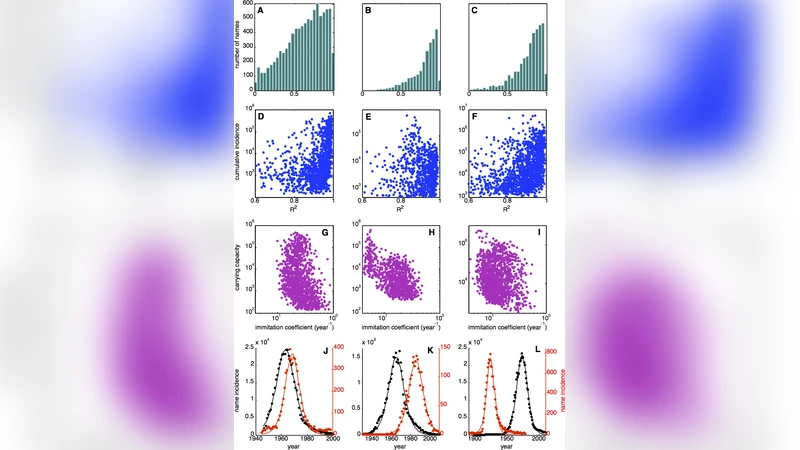
이 논문은 ‘패션’이라는 사회문화 현상을 내구재 시장에서 사용되는 Bass 확산 모델과 직접 연계한다는 점에서 독창적이다. Bass 모델은 혁신 계수(p)와 모방 계수(q), 그리고 시장 규모(K)라는 세 변수로 제품 채택 과정을 기술한다. 저자들은 이름 선택에서는 매스미디어 효과가 미미하다고 가정하고(p=0) 이를 로지스틱 성장식으로 단순화한다. 로지스틱 모델은 dN/dt = q N (1‑N/K) 형태이며, 여기서 N은 연도별 이름 사용 횟수, q는 ‘모방 강도’, K는 해당 이름이 도달할 수 있는 최대 보유자 수(즉, ‘수용 한계’)를 의미한다.
데이터는 프랑스(INSEE), 네덜란드(Nederlandse Voornamenbank), 미국(SSA) 세 국가의 전국 규모 출생명 기록을 사용했으며, 각각 1900‑2008, 1880‑2010, 1880‑2011 기간을 포괄한다. 이름별 시계열을 최소 60년 이상 연속 데이터로 제한하고, 비정상적 피팅(수렴 실패, 피크가 관측 기간 외, 피크 폭이 기간보다 넓은 경우)을 30% 이하로 제외하였다. 남은 시계열에 대해 비선형 최소제곱법으로 로지스틱 파라미터(q, K)를 추정하고, 적합도는 Nash‑Sutcliffe 효율지수(R²)로 평가했다.
주요 결과는 다음과 같다. (1) 전체 시계열 중 평균 85% 이상(프랑스·네덜란드·미국 모두) 연도별 출생명 총량을 설명할 수 있었으며, ‘잘 맞는’ 시계열(두 단계 R²>0.6)도 각각 9‑31% 정도 존재했다. (2) R²와 누적 발생 횟수 사이에는 약한 양의 상관관계가 있었지만, 낮은 빈도의 이름에서도 높은 적합도가 관측돼 ‘패션’이 인기와 독립적으로 발생한다는 점을 시사한다. (3) K와 q는 거의 독립적으로 분포했으며, K는 3‑4자리 수 차이까지 변동하는 반면 q는 0.04‑1 사이에 좁게 모여 있었다. 이는 이름이 얼마나 많은 사람에게 퍼질지는 개별적이지만, 전파 속도(모방 강도)는 문화적·사회적 요인에 의해 제한된다는 의미다.
예측 능력도 검증되었다. 프랑스 이름 ‘Florine’에 대해 1999년까지의 데이터를 이용해 파라미터를 추정한 뒤, 2000‑2008년 실제 발생량을 예측했으며, 관측값과 모델값이 신뢰구간 내에서 일치하였다. 이는 로지스틱 모델이 단순히 사후 적합에 그치지 않고, 미래 트렌드 예측에도 활용 가능함을 보여준다.
이론적 논의에서는 기존 이름 연구가 ‘인기’를 ‘패션’과 동일시하는 한계를 지적하고, 사회계층 모방·전통 파생 두 가지 사회학적 메커니즘을 언급한다. 저자는 로지스틱 모델이 이러한 메커니즘을 정량화하는 최소 파라미터(두 개)로 충분히 설명할 수 있음을 주장한다. 또한, 이름이 매스미디어에 의해 크게 영향을 받지 않으므로 Bass 모델의 혁신 파라미터(p)를 0으로 두는 것이 합리적이며, 이는 ‘전염성’·‘사회적 상호작용’에 기반한 확산을 강조한다.
한계점으로는 전통적으로 부모에게 물려받는 이름(전달형)이나, 문화적·지리적 네트워크가 복합적으로 작용하는 경우를 모델에 포함시키지 못했다는 점을 들었다. 향후 연구에서는 이름의 어근·접미사 등 부분적 패션, 공간적 확산, 그리고 다중 사회집단이 동시에 진화하는 동적 모델을 확장할 여지가 있다.
전반적으로 이 논문은 마케팅 확산 이론을 인구학·문화학에 성공적으로 이식함으로써, 이름이라는 일상적 현상의 정량적 예측과 사회적 메커니즘 해석을 동시에 제공한다는 점에서 학제간 연구의 좋은 사례라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기