OCCA 멀티스레딩 언어 통합 프레임워크
초록
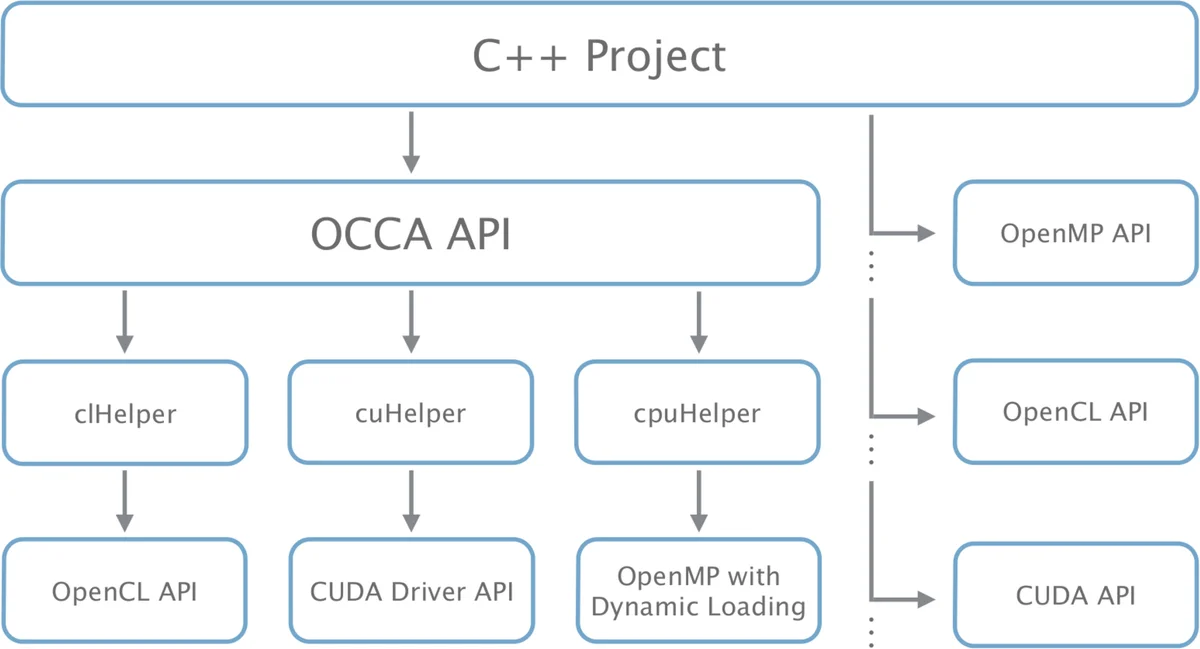
OCCA는 C++ 기반 라이브러리로, 런타임 컴파일과 매크로 전개를 이용해 단일 커널 소스를 OpenMP, OpenCL, CUDA 등 여러 스레딩 언어로 자동 변환한다. 호스트‑디바이스 인터페이스를 추상화하고, 메모리 관리와 커널 호출을 일관된 API로 제공함으로써 다양한 하드웨어에서 이식성과 고성능을 동시에 달성한다.
상세 분석
본 논문은 현대 HPC 환경에서 지속 가능한 프로그래밍 모델이 부재함을 지적하고, 이를 해결하기 위한 OCCA 프레임워크를 제안한다. OCCA의 핵심은 ‘단일 커널 언어’를 매크로 기반으로 정의하고, 런타임에 선택된 백엔드(OpenMP, OpenCL, CUDA)로 전처리·컴파일하는 점이다. 매크로 집합은 워크그룹·워크아이템 개념을 추상화하여 GPU 전용 구문을 OpenMP의 pragma 형태로 매핑한다. 예를 들어 occaOuterFor와 occaInnerFor 매크로는 각각 블록 차원과 스레드 차원의 루프를 생성하고, occaBarrier는 로컬·글로벌 메모리 동기화를 제공한다. 이러한 설계는 소스 코드 레벨에서 언어 간 차이를 최소화하면서도, 각 백엔드가 제공하는 최적화 기회를 보존한다.
호스트 측 API는 occaDevice, occaMemory, occaKernel 클래스로 구성된다. occaDevice는 선택된 디바이스에 대한 컨텍스트와 커맨드 큐를 생성하고, 메모리 할당·커널 컴파일을 담당한다. occaMemory는 디바이스 메모리 핸들을 캡슐화하지만, 실제 데이터 전송 시점은 프로그래머가 명시하도록 하여 성능 제어권을 유지한다. occaKernel은 함수 포인터(OpenMP), cl_kernel(OpenCL), CUfunction(CUDA) 등을 통합 인터페이스로 감싸며, 커널 실행 시 그리드·블록 크기를 매크로 인자로 전달한다.
런타임 컴파일은 OpenCL과 CUDA의 경우 JIT(Just‑In‑Time) 방식을, OpenMP는 컴파일 타임에 pragma을 삽입하는 방식을 사용한다. 따라서 새로운 백엔드가 추가될 경우 매크로 정의만 확장하면 기존 커널 코드를 그대로 재사용할 수 있다. 논문은 유한 차분, 스펙트럴 엘리먼트, 불연속 갈레킨 방법을 구현한 사례를 통해, 동일한 OCCA 커널이 CPU와 GPU, 그리고 Xeon Phi와 같은 이기종 아키텍처에서 경쟁력 있는 성능을 보임을 실험적으로 입증한다.
또한 OCCA는 기존의 소스‑투‑소스 변환 도구(예: Swan, CU2CL)와 달리, 전처리 단계에서 매크로 전개만으로 언어 변환을 수행하므로 빌드 파이프라인이 단순해지고, 디버깅이 용이해진다. 메모리 관리와 동기화 메커니즘을 명시적으로 제공함으로써, OpenMP의 순차적 워크아이템 실행과 GPU의 병렬 워크아이템 실행 사이의 차이를 프로그래머가 인식하고 최적화할 수 있다. 전체적으로 OCCA는 이식성, 유지보수성, 성능을 동시에 만족시키는 실용적인 통합 접근법으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기