선거 연구를 위한 순위 데이터 혼합 전문가 모델
초록
본 논문은 아일랜드 대통령 선거의 순위 투표 데이터를 이용해, 투표 블록(유사한 선호를 가진 유권자 집단)을 식별하고 사회적 요인(연령, 정부 만족도 등)이 블록 구성에 미치는 영향을 분석한다. 이를 위해 순위 데이터에 적합한 Benter 모델을 구성요소 밀도로 사용하고, 혼합 전문가(Mixture of Experts) 프레임워크를 도입해 혼합 비율을 공변량 함수로 모델링한다. EM‑MM 하이브리드 알고리즘으로 파라미터를 추정한 결과, 명확한 투표 블록이 존재함을 확인하고 연령과 정부 만족도가 주요 설명 변수임을 밝혀냈다.
상세 분석
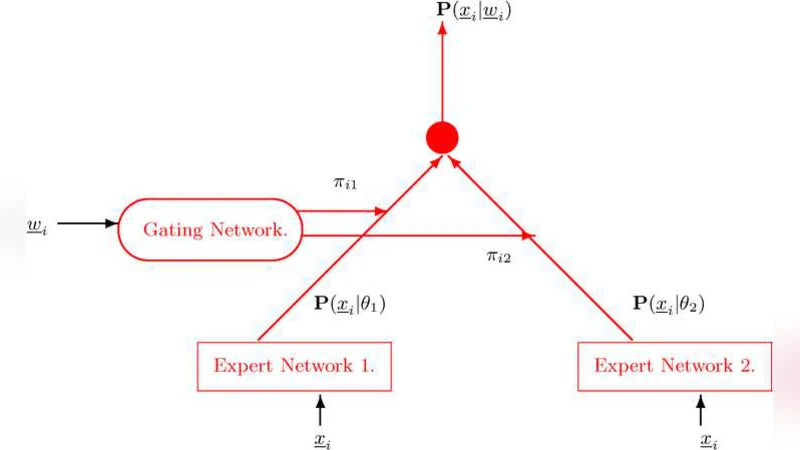
이 연구는 순위형 설문 데이터에 대한 군집 분석을 위해 기존의 혼합 모델을 확장한 ‘혼합 전문가(Mixture of Experts)’ 접근법을 제시한다. 핵심은 두 가지 요소이다. 첫째, 각 군집(전문가)의 확률밀도 함수로 Benter 모델을 채택했는데, 이는 순위 데이터의 단계별 선택 확률을 파라미터화하여 후보 간 선호 강도를 정밀히 포착한다. Benter 모델은 순위가 길어질수록 감소하는 선택 강도를 반영하는 ‘감쇠 파라미터’를 포함해, 실제 투표에서 흔히 나타나는 ‘후보 선호의 급격한 감소’를 모델링한다는 점에서 적합하다.
둘째, 혼합 비율을 고정된 값이 아니라 사회·인구학적 공변량의 함수로 설정했다. 이를 위해 일반화 선형 모델(GLM) 구조를 차용해 로짓 링크를 사용, 각 유권자의 연령, 성별, 교육 수준, 정부 만족도 등 다양한 변수들이 특정 블록에 속할 확률에 미치는 영향을 추정한다. 이렇게 하면 군집 결과가 사후 분석이 아니라 사전 예측 변수와 직접 연결돼, 정책 입안자나 캠페인 전략가가 특정 인구 집단을 목표로 하는 전략을 설계할 수 있다.
모델 추정은 EM 알고리즘의 E‑step에서 각 유권자의 블록 소속 확률(책임도)을 계산하고, M‑step에서는 Benter 파라미터와 GLM 회귀계수를 동시에 업데이트한다. Benter 파라미터는 직접적인 최대우도 해가 존재하지 않아 MM(Minorization‑Maximization) 절차를 도입, 하한 함수를 구성해 단계별 파라미터를 상승시킨다. EM과 MM을 결합한 하이브리드 방식은 수렴 속도를 높이고, 복잡한 비선형 구조에서도 안정적인 추정을 가능하게 한다.
실증 분석에서는 2011년 아일랜드 대통령 선거 데이터를 사용했다. 후보자는 5명이며, 유권자는 평균 3~4개의 순위를 제공했다. 최적 군집 수는 BIC 기준으로 3개가 선택되었으며, 각 군집은 ‘전통적 보수층’, ‘진보적 젊은층’, ‘중도·정부 만족도 높은 층’으로 해석된다. 회귀 결과는 연령이 증가할수록 보수층에 속할 확률이 높아지고, 정부 만족도가 높을수록 중도층에 속할 가능성이 크게 증가함을 보여준다. 또한, 성별·교육 수준은 상대적으로 미미한 영향을 미쳤다.
이러한 결과는 순위 데이터와 공변량을 동시에 고려한 혼합 전문가 모델이 전통적인 군집 분석보다 더 풍부한 인사이트를 제공함을 증명한다. 특히, 정책·선거 전략 수립 시 인구통계학적 변수와 선호 구조를 연결짓는 정량적 근거를 제공한다는 점에서 학문적·실무적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기