희소코드 기반 얼굴 이미지 검색 연구 동향
초록
본 논문은 대규모 얼굴 이미지 데이터베이스에서 시각적 내용에 기반한 검색을 구현하기 위해 최근 사용되는 희소 표현 기법과 다양한 얼굴 특징 추출 방법을 종합적으로 정리한다. 디지털 기기와 사진 공유 서비스의 급증으로 얼굴 이미지가 폭증함에 따라, 효율적인 인덱싱과 검색이 핵심 과제로 떠올랐다. 저자는 희소 코딩이 특징 벡터의 차원을 크게 줄이면서도 판별력을 유지해 검색 정확도와 속도를 동시에 향상시킬 수 있음을 강조한다. 또한, 전통적인 텍스처·형태 기반 특징과 딥러닝 기반 임베딩을 결합한 하이브리드 접근법, 그리고 사전 학습된 사전(dictionary)와 라벨링 전략에 대한 최신 연구들을 비교 분석한다. 마지막으로, 현재의 한계점과 향후 연구 방향을 제시한다.
상세 분석
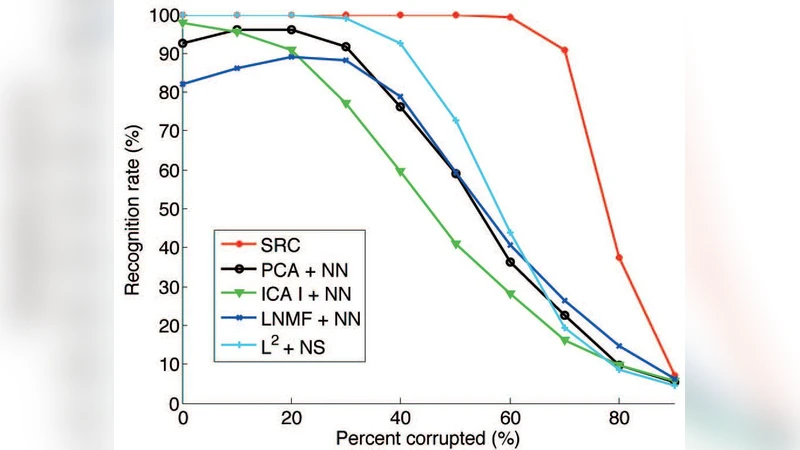
본 설문 논문은 얼굴 이미지 검색 시스템을 설계할 때 가장 핵심이 되는 두 축, 즉 ‘특징 추출(FEATURE EXTRACTION)’과 ‘인덱싱·검색(INDEXING & RETRIEVAL)’에 초점을 맞추어 희소 코딩(sparse coding) 기반 접근법을 중심으로 전반적인 흐름을 정리한다. 먼저, 얼굴 이미지에서 추출되는 전통적인 특징으로는 LBP(Local Binary Patterns), Gabor 필터, HOG(Histogram of Oriented Gradients) 등이 있다. 이들 특징은 지역 텍스처와 구조 정보를 효과적으로 포착하지만, 차원 수가 높고 중복성이 커서 대규모 데이터베이스에 직접 적용하면 메모리와 연산 비용이 급증한다. 이를 해결하기 위해 최근 연구에서는 ‘희소 코딩’이라는 압축 표현 방식을 도입한다. 희소 코딩은 입력 특징 벡터를 사전(dictionary)이라 불리는 과잉(over-complete) 기저 집합 위에 희소하게 표현함으로써, 원본 차원을 크게 감소시키면서도 중요한 구조적 정보를 보존한다. 이 과정에서 L1 정규화 기반 최적화, OMP(Orthogonal Matching Pursuit)와 같은 탐욕 알고리즘, 혹은 딥러닝 기반 자동 인코더가 활용된다.
희소 코딩의 장점은 크게 세 가지로 요약할 수 있다. 첫째, 차원 축소 후에도 높은 판별성을 유지한다는 점이다. 사전 학습 단계에서 다양한 얼굴 변형(조명, 표정, 포즈)을 포함한 샘플을 사용하면, 사전 자체가 변형에 강인한 기저를 형성하게 된다. 둘째, 인덱싱 효율성이 크게 향상된다. 희소 벡터는 대부분이 0인 구조이므로, 역인덱스(inverted index)나 해시 기반 구조를 적용했을 때 메모리 사용량이 크게 감소하고, 검색 시 거리 계산도 비제로 성분만 고려하면 되므로 연산량이 감소한다. 셋째, 다른 특징과의 융합이 용이하다. 예를 들어, 딥러닝 기반 얼굴 임베딩(예: FaceNet, ArcFace)과 전통적인 텍스처 특징을 각각 희소 코딩한 뒤, 다중 모달 벡터를 결합하면 서로 보완적인 정보를 제공한다. 논문은 이러한 하이브리드 전략이 특히 ‘쿼리 이미지와 데이터베이스 이미지 간의 도메인 차이’를 완화하는 데 효과적이라고 지적한다.
또한, 사전(dictionary) 구축 방법에 대한 논의도 상세히 다룬다. K‑means, K‑SVD, 온라인 딕셔너리 학습 등 다양한 알고리즘이 소개되며, 각각의 수렴 속도와 사전 크기 선택이 검색 성능에 미치는 영향을 실험 결과와 함께 비교한다. 특히, 온라인 딕셔너리 학습은 데이터가 지속적으로 추가되는 실시간 시스템에 적합하다는 점에서 주목받는다. 사전 크기가 지나치게 크면 희소성(sparsity)이 감소해 연산 효율이 떨어지고, 반대로 너무 작으면 표현력이 제한돼 정확도가 저하된다. 따라서 ‘희소도(ℓ0 혹은 ℓ1 노름)’와 ‘재구성 오류(reconstruction error)’ 사이의 트레이드오프를 어떻게 조절하느냐가 핵심 설계 변수로 제시된다.
검색 단계에서는 거리 측정(metric) 선택도 중요한 변수다. 유클리드 거리, 코사인 유사도, χ² 거리 등 다양한 메트릭이 실험을 통해 비교되며, 특히 희소 벡터의 경우 코사인 유사도가 높은 판별력을 보이는 경우가 많다. 또한, ‘다중 레벨 인덱싱(multi‑level indexing)’ 기법을 도입해 coarse‑to‑fine 전략을 구현하면, 초기 단계에서 대략적인 후보군을 빠르게 추출하고, 후속 단계에서 정교한 재정렬을 수행해 전체 검색 시간을 크게 단축할 수 있다.
마지막으로, 현재의 한계점으로는 (1) 사전 학습에 필요한 대규모 라벨링 데이터, (2) 실시간 시스템에서의 사전 업데이트 비용, (3) 얼굴 이미지의 극단적인 변형(예: 마스크, 저해상도)에서의 표현력 저하 등을 꼽는다. 향후 연구 방향으로는 ‘비지도/약지도 딥러닝 기반 사전 학습’, ‘동적 사전 관리(dynamic dictionary adaptation)’, 그리고 ‘멀티모달(음성, 텍스트)와의 연계’를 제시한다. 이러한 방향은 희소 코딩이 얼굴 이미지 검색뿐 아니라 일반적인 시각 검색 분야에서도 지속 가능한 핵심 기술로 자리매김할 가능성을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기