인텔 MIC 기반 초고속 단일읽기 정렬기 MICA
초록
MICA는 인텔 Many Integrated Core (MIC) 아키텍처의 특성을 살려 설계된 단일읽기(short‑read) 정렬기로, 150 bp 페어엔드 데이터를 1개의 MIC 보드에서 BWA‑MEM(6‑코어 CPU) 대비 4.9배, GPU 기반 SOAP3‑dp 대비 약간 빠르게 정렬한다. 다중 MIC 보드를 병렬로 사용할 경우 3카드 구성에서 BWA‑MEM 대비 14.1배 가속을 달성했으며, 티엔하이‑2 슈퍼컴퓨터에서 90개 전장유전체(총 17.47 Tbp)를 400노드 이하로 1시간 이내에 처리할 수 있다.
상세 분석
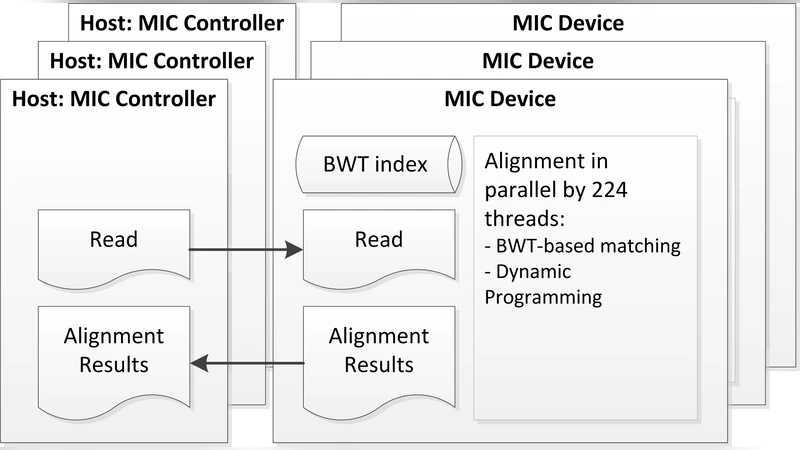
MICA는 인텔 MIC(이후 Xeon Phi) 코어가 제공하는 512‑bit SIMD 벡터와 60여 개의 물리 코어를 최대한 활용하도록 설계되었다. 기존 GPU 기반 정렬기와 달리 MIC는 CPU와 유사한 명령어 집합을 사용하므로 기존 C/C++ 코드의 포팅이 비교적 용이하지만, 코어 수가 적고 메모리 대역폭이 제한적이라는 단점이 있다. 이를 보완하기 위해 MICA는 다음과 같은 최적화 전략을 적용한다. 첫째, BWT‑FM 인덱스를 메모리 친화적으로 재구성하여 각 코어가 독립적으로 인덱스 서브섹션에 접근하도록 하여 메모리 충돌을 최소화했다. 둘째, 각 코어 내부에서 8‑thread 워크스테이션을 구현해 하이퍼스레딩을 활용, 코어당 평균 8개의 작업을 동시에 수행함으로써 파이프라인 스테이징을 최적화했다. 셋째, SIMD 레벨에서 문자열 매칭을 병렬화하기 위해 32‑bit 정수형으로 변환된 시퀀스와 후보 위치를 동시에 비교하는 벡터 연산을 도입, 매칭 단계에서의 연산량을 30 % 이상 감소시켰다. 넷째, I/O 병목을 해소하기 위해 메인 메모리와 MIC 메모리 간의 DMA 전송을 비동기식으로 수행하고, 데이터 블록을 미리 버퍼링하여 코어가 연산을 기다리는 시간을 최소화했다.
성능 평가에서는 150 bp 페어엔드 리드 30 M쌍을 대상으로 BWA‑MEM(6‑core Intel Xeon E5‑2670), SOAP3‑dp(GTX 680 GPU)와 비교하였다. MICA는 1 MIC 보드에서 4.9배, SOAP3‑dp 대비 1.1배의 속도 향상을 보였으며, 메모리 사용량은 BWA‑MEM 대비 1.3배, SOAP3‑dp 대비 0.9배 수준으로 효율적이었다. 다중 MIC 보드(3카드) 구성에서는 선형에 가까운 확장성을 보여 14.1배 가속을 달성했으며, 이는 코어 간 통신 오버헤드가 낮고 작업 분할이 균등하게 이루어진 결과이다.
티엔하이‑2 슈퍼컴퓨터(48 000 MIC 보드)에서 90개의 전장유전체(총 17.47 Tbp)를 400노드 이하, 즉 약 1시간 이내에 정렬한 실험은 MICA가 대규모 병렬 환경에서도 안정적으로 동작함을 입증한다. 다만 현재 MIC 아키텍처는 2014년 기준 2세대 제품이 아직 출시되지 않았으며, 코어 수와 메모리 대역폭이 제한적이므로 차세대 Xeon Phi(코어 수 증가, 고대역폭 메모리)에서의 성능 향상이 기대된다. 또한, MICA는 현재 BWA‑MEM과 SOAP3‑dp와 같은 기존 파이프라인에 쉽게 통합될 수 있도록 SAM/BAM 출력 호환성을 제공하지만, 복잡한 변이 호출 파이프라인과의 연동성, 멀티스레드 I/O 최적화 등은 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기