문학 작품 인물 장소 네트워크 추출 도구 CHAPLIN
초록
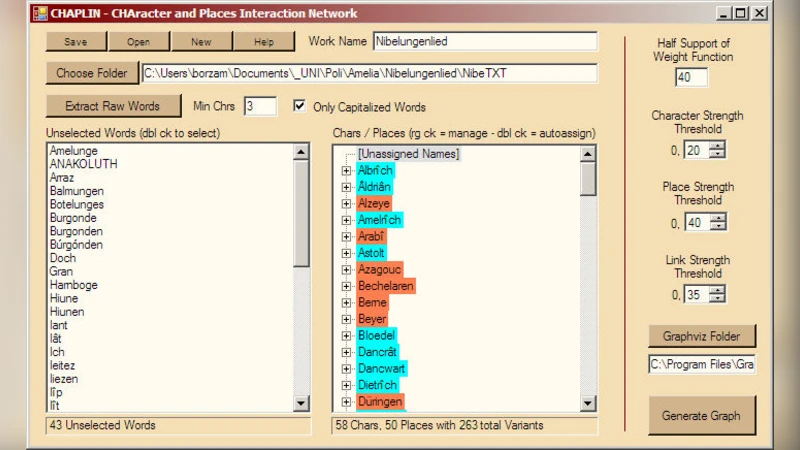
CHAPLIN은 서사 텍스트에서 인물과 장소를 자동으로 추출하고, 사용자가 선택한 이름을 기반으로 상호작용 네트워크를 생성하는 도구이다. 원시 단어 리스트를 만든 뒤, 인터페이스를 통해 이름을 지정하고, 사용자 정의 파라미터에 따라 그래프를 구축한다. 결과는 DOT 언어 형식의 GV 파일로 출력되어 Graphviz로 시각화할 수 있다.
상세 분석
본 논문은 서사 텍스트에서 사회적 관계를 정량화하기 위한 도구 CHAPLIN의 설계와 구현을 상세히 제시한다. 먼저 텍스트 전처리 단계에서 문장을 토큰화하고, 명사와 고유명사를 추출해 원시 단어 리스트를 만든다. 이 과정에서 VB.NET의 문자열 처리 기능과 정규표현식을 활용해 구두점과 불용어를 제거한다. 이후 사용자 인터페이스를 통해 연구자는 리스트에서 실제 인물·장소 이름을 선택한다. 선택된 이름은 내부 사전 구조에 저장되며, 각 이름에 대한 동의어와 변형 형태를 추가 입력할 수 있도록 설계돼 있다.
다음으로 상호작용 정의 단계에서는 사용자가 두 이름 사이의 관계를 판단하는 임계값(예: 최소 공동 등장 횟수)과 가중치(예: 대화량, 서술 빈도)를 설정한다. CHAPLIN은 텍스트 전체를 스캔하면서 선택된 이름들의 공동 등장 횟수를 카운트하고, 지정된 가중치에 따라 엣지의 강도를 계산한다. 엣지 라벨은 ‘performance’라는 개념으로, 등장 횟수와 대화 비중을 결합한 정규화된 값으로 표현된다.
그래프 생성은 DOT 언어 스크립트로 수행되며, 노드 속성(색상, 크기)은 등장 빈도에 따라 동적으로 할당된다. 엣지는 두 노드 간의 상호작용 강도에 따라 두께와 색상이 변한다. 최종 GV 파일은 Graphviz 엔진에 전달되어 PNG, SVG 등 다양한 포맷으로 시각화된다.
기술적으로 주목할 점은 CHAPLIN이 완전 자동화된 NER(Named Entity Recognition) 시스템이 아니라, 인간 전문가의 선택을 보조하는 하이브리드 접근법을 채택했다는 것이다. 이는 고전 문학처럼 고유명사가 변형되거나 희귀한 경우에도 정확도를 높일 수 있다. 또한 파라미터화된 가중치 체계는 연구 목적에 따라 네트워크의 민감도를 조절할 수 있게 해, 사회학적 분석부터 문학 비평까지 폭넓은 활용을 가능하게 한다.
한계점으로는 초기 단어 리스트 생성 시 어휘 사전 의존도가 높아, 언어적 다양성이 큰 텍스트에서는 누락이 발생할 수 있다. 또한 사용자 선택에 따라 결과가 크게 달라지므로, 재현성을 확보하려면 선택 기준을 명확히 문서화해야 한다. 향후 작업으로는 기계 학습 기반 NER 모듈을 통합해 자동 추출 정확도를 향상시키고, 다중 언어 지원 및 대규모 코퍼스 처리 성능을 개선하는 방안을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기